
In the complex and dynamic realm of data analytics, real-time anomalies serve as insights to issues a business faces. A pervasive and enduring conundrum persists: accurately discerning between anomalies of significant importance and those of lesser consequence. This distinction is a nontrivial task as not all anomalies bear the same weight. Certain deviations signal crucial disruptions demanding immediate rectification, while others merely reflect inconsequential deviations that bear no impact on the business. To address this predicament, Anodot has devised a transformative solution in the form of a feature termed “Alert Tuning Recommendations.”
Leveraging a sophisticated semi-supervised Machine Learning (ML) approach, and one of the largest labeled anomalies datasets known, Alert Tuning Recommendations strives to meticulously differentiate essential anomalies from insignificant ones. The paramount objective of this novel feature is to substantially minimize the occurrence of false positive alerts, whilst ensuring genuine alerts are not overlooked. By achieving this balance, this technology guarantees that users’ attention remains unequivocally focused on the most impactful business issues.
Underlying Mechanism of Alert Tuning Recommendations
The Alert Tuning Recommendations feature operates via a user-centric, semi-supervised learning process that can be elaborated in three distinct steps:
1. User Feedback on Anomalies: The first step engages users in an active manner, requesting their subjective evaluation of the anomalies detected by Anodot’s platform. Based on individual preferences and the impact on their specific use case, users can classify the anomalies into “good catches” or “not interesting.” For example, in the context of monitoring sales for a specific product, a negligible drop might be classified as “not interesting” due to its limited significance on overall sales performance. Figure 1 shows examples of a “good catch” and a “not interesting” alerts, with the main difference between the two being the total impact of the anomalies. 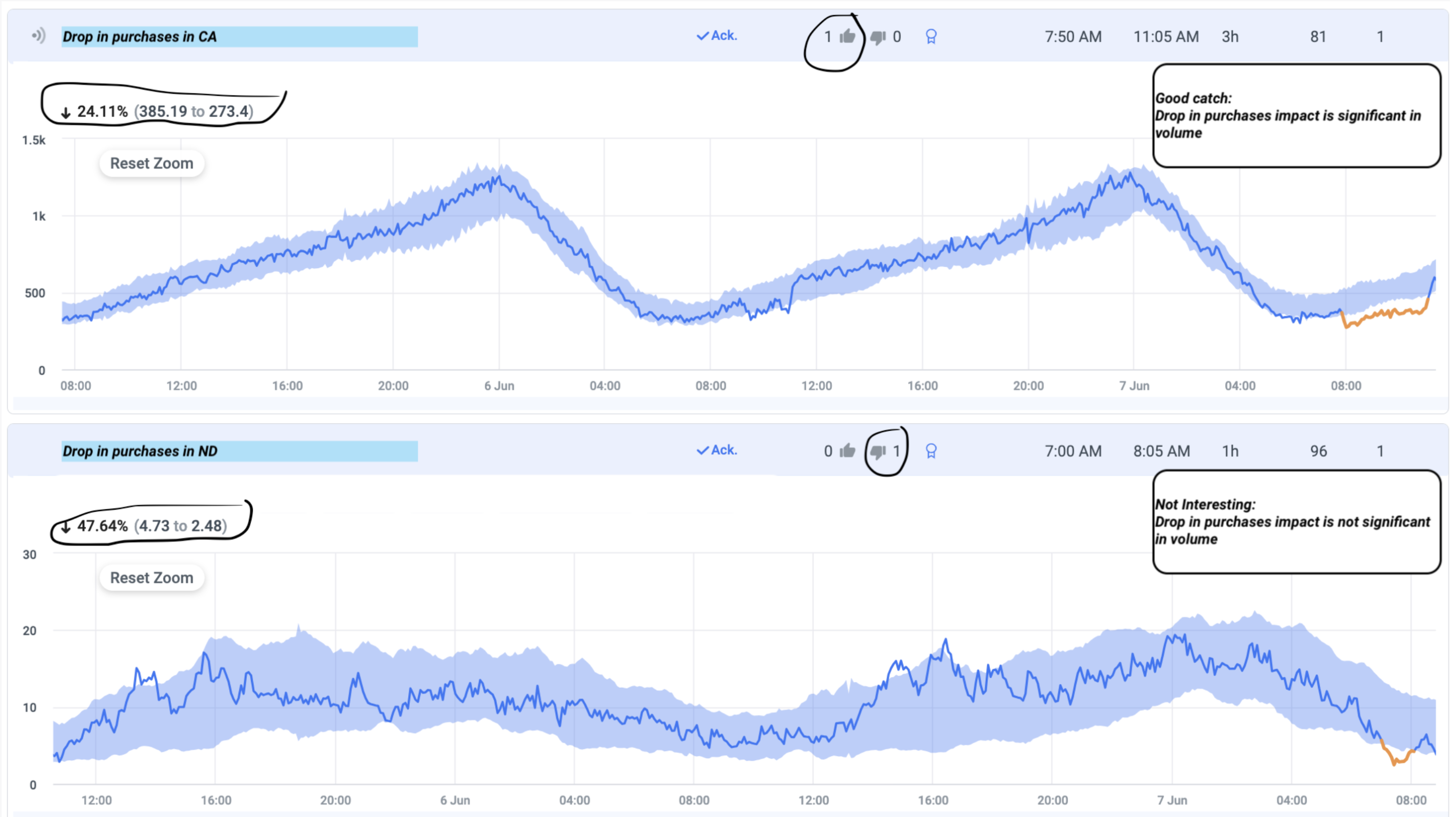 Figure 1: Two anomalies labeled by the user. The top is a good catch because of the volume of drop in purchases, while the second is marked as Not Interesting because the volume of the drop has minimal business impact.
Figure 1: Two anomalies labeled by the user. The top is a good catch because of the volume of drop in purchases, while the second is marked as Not Interesting because the volume of the drop has minimal business impact.
2. Anomaly Feedback Aggregation by Anodot: Subsequently, the platform assimilates the feedback provided by all the users, thereby gathering a comprehensive pool of classified anomaly data. This extensive, rich dataset serves as the cornerstone for the ensuing steps, ensuring the recommendations are grounded in substantial real-world feedback.
3. Activation of the Semi-supervised ML Auto-tune Service: This final stage deploys the semi-supervised ML auto-tune service, which utilizes the amassed user feedback to fine-tune alert parameters via a two-step mechanism:
a. Development of an XGBoost Classifier: Leveraging the prowess of the XGBoost algorithm, the platform constructs a classifier. This classifier is designed to segregate anomalies into “good catches” or “not interesting,” mirroring the classifications provided by users. Remarkably, the classifier’s training process is informed by an expansive dataset comprising over 100K anomalies that have been labeled by users across a span of three years, making it one of the largest labeled time-series anomaly datasets known to date. This classifier utilizes various inputs for the training process, including attributes of the anomaly, metadata associated with the time series, and other intricate features, thereby ensuring a holistic analysis.
b. Auto-tuning Alert Parameters: For each set of time series metrics that a user expresses interest in monitoring, the system undertakes a rigorous exploration of past anomalies. Unlabeled anomalies are probabilistically labeled by the trained classifier, while known user feedback is assigned to the labeled anomalies. Then, employing these labeled anomalies, the system determines the key attributes that characterize a “good catch” anomaly, heavily weighting towards anomalies reinforced by user feedback. Consequently, an optimal assortment of anomaly characteristics that warrant alert triggers is selected, effectively reducing false positives without curtailing the true positive rate.
The culmination of this process is a set of recommendations for alert attributes, which is then presented to the user through the Anodot interface. Figure 2 shows a screenshot of recommendations for a user, with the ability to accept or ignore a recommendation (or part of a recommendation).
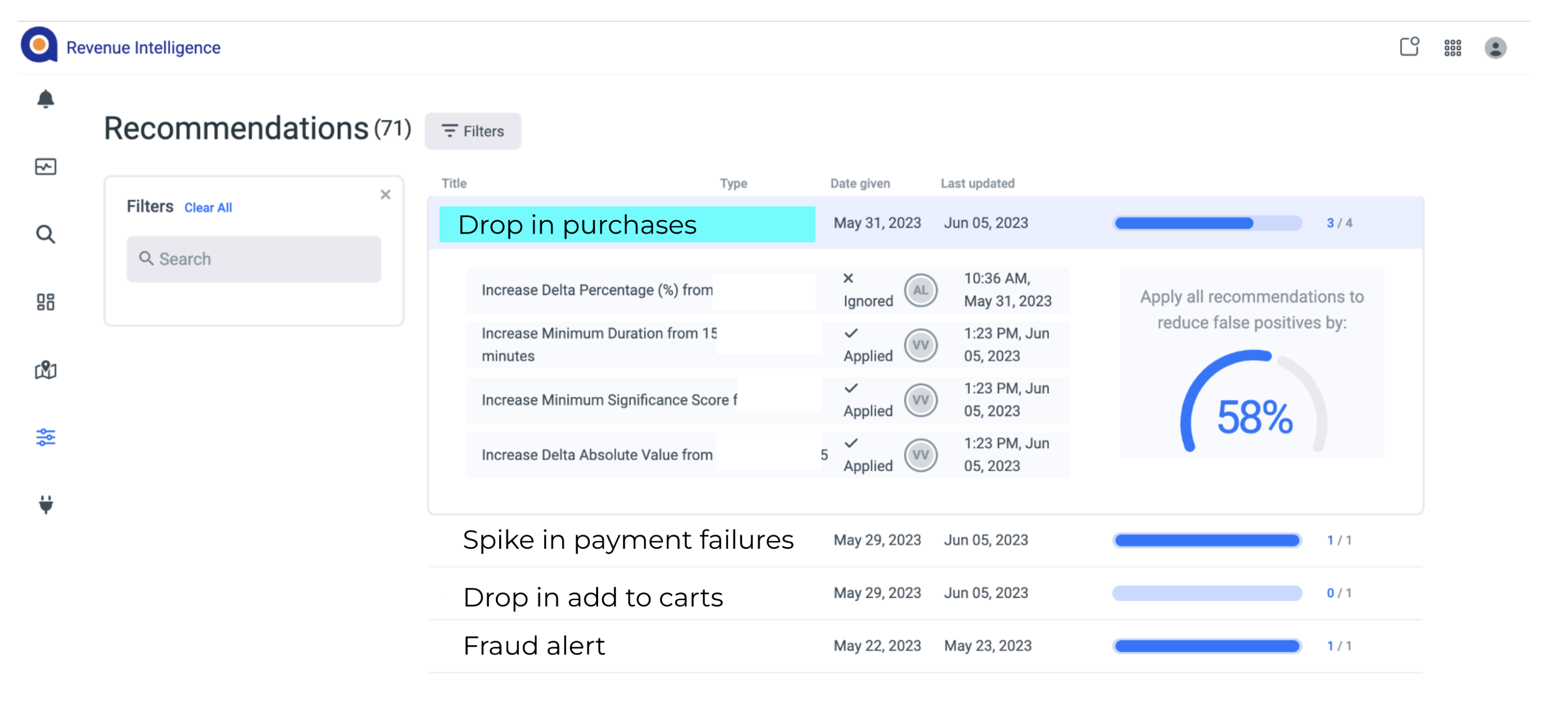
Figure 2: The auto-tune recommendation screen. The user can select which recommendations to accept or reject and is shown the expected reduction in false positive rate.
The Implications and Impact of Alert Tuning Recommendations
The Alert Tuning Recommendations feature signifies a notable stride in data-driven decision-making. With its deployment across Anodot’s customer base, this feature has evidenced its efficacy by markedly reducing false positive rates, in certain instances by a striking margin of over 60%. This feature thus capacitates users to concentrate their attention exclusively on alerts of genuine significance, enhancing both efficiency and productivity.
The amalgamation of human feedback and cutting-edge ML techniques, as exemplified by Alert Tuning Recommendations, exemplifies Anodot’s commitment to advancing user-focused solutions that effectively harness the power of data to drive decision-making.
Concluding Remarks
As we traverse an increasingly data-centric world, the capacity to segregate valuable signals from superfluous noise assumes paramount importance. Anodot’s Alert Tuning Recommendations represents an innovative solution to this quandary. By integrating user feedback with ML-driven analysis, Anodot is consistently redefining the boundaries of anomaly detection and alerting. By juxtaposing human intuition and AI precision, this feature ensures your focus remains trained on the most pertinent data points, thereby streamlining operations and enhancing efficacy.
Written by Ira Cohen
Start optimizing your cloud costs today!
Connect with one of our cloud cost management specialists to learn how Anodot can help your organization control costs, optimize resources and reduce cloud waste.


