In Anodot’s webinar on time series anomaly detection, industry experts Arun Kejariwal, Ira Cohen and Ben Lorica shared hard-won insights on successfully implementing and executing anomaly detection systems in today’s increasingly complex business environment.

Arun Kejariwal is an authority on machine learning applications in business; Ira Cohen is the Chief Data Scientist and Co-Founder of Anodot, which provides ML anomaly detection and forecasting for big data organizations; and Ben Lorica is the Chief Data Scientist at O’Reilly Media. During the webinar, these three experts covered:
- Business value for time series anomaly detection
- Cost of not having anomaly detection in place
- What defines a time series, machine learning anomaly detection system
- Requirements for a successful anomaly detection system
The Cost of Not Detecting Anomalies in Time
Time series anomaly detection relates to any data associated with time (daily, hourly, monthly, etc.); for example, daily revenue at a retail store represents time series data at the day level.
For eCommerce businesses, monitoring time series data could be anything from tracking how many visitors you have on your site to when and how people are purchasing on your site. For a telco company, that could be network usage at any given moment or the response time for their call centers. And these metrics can incredibly granular – down to the device and browser level – which makes monitoring and investigating anomalies extremely cumbersome.
Organizations today are managing millions, even billions of these metrics, and finding abnormal behavior with dashboards and setting static-threshold alerts is challenging to say the least. Anomalies can easily go undetected.
One of the biggest takeaways of the webinar was that when it comes to time series anomaly detection, businesses simply can’t afford to discover these anomalies when it’s too late. Just how much so was recently revealed in a recent Gartner study, which found that incidents can cost large enterprises an average of $300,000 an hour, and that the average loss to productivity is 31 hours a week.

Anomaly detection, according to Cohen, is the cure for this. “Anomaly detection is the way to find all these incidents as quickly as possible before they end up costing too much. We’ve seen several examples in recent years of this – from Target’s checkout outages to HSBC’s mobile banking app failure and more. The resulting damage to a brand in both time and reputation can be significant.”
Automated Anomaly Detection: A Hidden Key to Your Business
The experts emphasized that anomaly detection is not only limited to IT metrics, but that it applies to business metrics as well. As Kejariwal noted, “When I was at Twitter, we tracked important business metrics such as the number of tweets per second or the number of followers or retweets per second. When we saw a sudden drop to what we expected, that constituted an anomaly – or a deviation from an expected pattern. Historically, metrics such as these were detected by dashboards. But to accurately monitor the hundreds of millions of time series that now exist, it’s not viable or scalable to monitor and detect anomalies this way anymore.”
Anomaly detection uses many of the algorithms in machine learning, and looks for outliers. When executed correctly, these alerts operate in real time and offer context – correlating each incident to similar anomalies, relevant factors and the potential root cause. These are capabilities that BI/data visualization tools simply can’t capture alone.
Requirements for Successful Anomaly Detection
The webinar participants went on to cover several requirements for a successful anomaly detection system. These include:
- Real-time capabilities
- Scalability
- Accuracy: false-positives vs. false-negatives
- Compliance
- Transparency
- And more…
The experts discussed how anomaly detection should be comprehensive, continuous, adaptive and accurate, and how irrelevant data ‘noise’ should be filtered down to relevant insights that can be processed in real time.
This all means not simply having the ability to process a lot of data in real time, but to also find anomalies without any human involvement. The idea of being truly autonomous means a system that can learn practically everything on its own, with minimum to no human intervention.
The Pitfalls of Using Open Source Solutions
The experts also discussed the rapid increase in the last few years of organizations developing in-house, open source solutions to tackle the challenge of anomaly detection. Those considering buying these types of systems, however, should consider not only budget, but processes for how to evaluate systems or even models from third parties.
Kejariwal said the open source solution he developed and managed at Twitter had its limitations.
“When we were working on Twitter open source,“ Kejariwal said, “timeliness and real-time detection were both very important. If the system caught an anomaly that warranted action, but you only found it two hours later, that would result in a poor user experience and low adoption, where users couldn’t tweet or retweet and so on. So in this case timeliness was critical.”
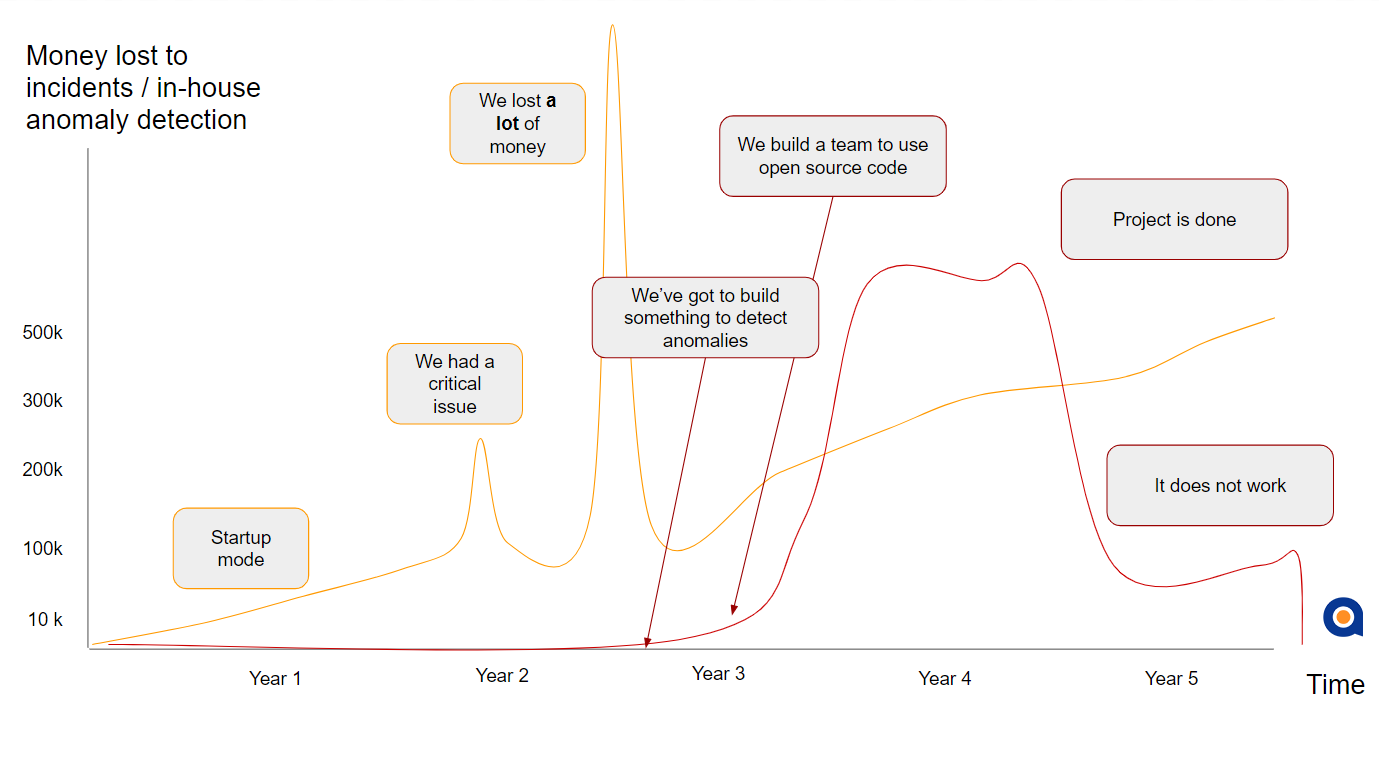
Cohen expanded on this point as well, stating that it’s easy to get something working with some of the data using open source, but to have a system that understands scale and time series, you need to have models that take into account the dynamics of what you’re measuring. “You might decide to create a team around an in-house solution with a data scientist or two, and you may do some testing to try to define the product,” Cohen said. “You’re spending time and money but not really resolving your incidents; you just hope you don’t get hit with another big incident before the project is over. The key is for these types of solutions to be thought of not as a one-time project, but as a product that needs to be built and maintained over the long haul. When it’s not, it’s almost always destined to fail.”
View the webinar to learn more about how to successfully utilize time series anomaly detection for your business.


