
Getting the right metrics at the right time could be the difference between running a smooth operation and making costly mistakes. And yet, data delays are still very much a part of data analysis today.
Data Delay & Composite Metrics
Online businesses generating big data often use a combination of metrics in their analytics decision-making.
For example, an eCommerce business that wants to optimize its ad targeting has less use for total sales number. To create a targeted ad, the business would need a composite metric of total in-app purchases of a specific product, made by returning users from a specific age group, in a specific region, over a specific time frame.
Sifting through the entire database to generate accurate results is complicated. Not only does it involve collecting various pieces of data, but the metrics required each have their own data delay.
This is exactly where things can get complicated. Not all the metrics are available at the same time. What percentage of the relevant metrics have to be ready in order to move forward? How can you calculate this composite metric in a timely manner?
That’s the crux of our challenge: determining scheduling to minimize data delays. Keep reading to see how our company decided to resolve the issue.
Manual and Historical Scheduling
When displaying results to our clients, we use predetermined time scales, or “roll-ups” for displaying the data. The data is collected every minute, 5 minutes, hour, day or week, depending on each client’s preferences. Each roll-up contains the data gathered up until that point – which can cause problems.
For example, if a composite metric requires different samples, that are generated at different intervals, it could be difficult to determine the precise point in time in which the calculation should be scheduled.
The problem could be addressed using different forms of scheduling.
One method is manual, which is based on the client’s own familiarity with their processes. This method could be effective, but also has many disadvantages. There’s always a trade-off: If you calculate a composite metric at set time periods, you’ll need to compensate for delays and incomplete data.
Think of this process like a tour guide who works with a travel agency to book registrants for her 12 p.m. tour. In the case of manual scheduling, that guide (aka the customer) doesn’t know when all the registrants (aka the data) will show up, but she doesn’t want to wait forever to find out. She knows most of the group usually shows up by 12:15 p.m., so she always starts the tour then, no matter if everyone hasn’t showed up.

Another form is historical scheduling. This method chooses when to perform the calculation based on historical data completion.
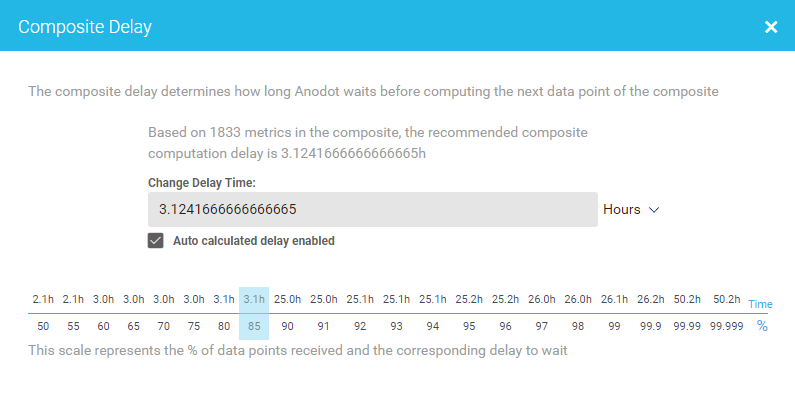
For example, if you decide 85 percent of data completion is adequate for calculation and you don’t need to wait for 100 percent, the algorithm will determine the best time to guarantee that percentage. That time will usually fluctuate and the system adapts. This is a good method for customers whose data delivery is usually constant, but occasionally fluctuates.
While this is a fully automated process, it also comes with a disadvantage: if a certain metric happens to experience a significant delay you risk incomplete composites and inaccurate analytics. Remember, it’s using historical data to determine the best calculation time, not how the data streams are operating in real time. If your data is running late one day, it will still get calculated at the time that worked best previously.
Applying the tour guide example, historical scheduling is as if the guide starts recording arrival times each day to determine what percentage of registrants show up and how late. She decides she’s fine with starting the tour (aka calculating metrics) as soon as 85 percent (or more) of registrants have shown up – which recent records indicate happens by 12:20 p.m.

Watermark Scheduling
The third method, watermark scheduling, is the newest form available to our customers.
We have started advocating this type of scheduling over the others because it’s proven to be a much more accurate way of determining when you’ll get the most complete data.
This is how it works. As opposed to manual and historical scheduling — which calculate data at set time frames, even if it isn’t all there — watermark scheduling is based on how the data streams are running in real time. It doesn’t calculate composite metrics until all available data samples for a time frame or “bucket” have arrived and there’s no need to wait anymore. There’s no guesswork.
In the case of the tour guide, watermark scheduling is as if the guide calls the travel agency (aka data service providers) to find out how many registrants she should be expecting that particular day and she waits until all of them get there before starting the tour.

This works differently depending on the data source. For services such as Google Analytics and Adobe Analytics, Anodot pulls the data at their guaranteed delivery times. For example, Adobe guarantees 100 percent data completion after two hours. And with Anodot’s S3 data collector, we probe for the files and if they aren’t available, we wait. It’s an all-or-nothing calculation.
When it comes to composite metrics, you no longer have to wonder whether you should wait for metrics that haven’t yet arrived. Calculations are performed only when the data is ready. And if you don’t have the calculation, you know there’s something wrong on your end.
So which is best?
For customers who prioritize accuracy over speed, watermark scheduling is the way to go. Others may value expediency and they may decide history or manual scheduling is better suited for their needs.
Hopefully this article will help you better understand which type of data scheduling is right for you.


