
In this final installment of our three-part series, let’s recap our previous discussions of anomalies – what they are and why we need to find them. Our starting point for this discussion was that every business has many metrics that they record and analyze on a periodic basis. Each of these business metrics takes the form of a time series of data, and each time series has a normal baseline of behavior.
The Importance of Anomaly Detection
For some metrics, it may be a seasonal pattern, others may exhibit a trend over time, and others will be distributed tightly around some nominal value. If a data point deviates outside the expected range for that metric at a particular point in time, that data point is considered an anomaly.
Since business metrics report data relating to some facet of business performance, an anomaly can reflect an important event or change in the business, possibly affecting the revenue stream. The anomaly in the data could be a sign of an opportunity to earn more money – or of an issue that’s negatively affecting the bottom line.
The Need for Automated Anomaly Detection
Either way, companies need to know what their data is telling them in real time y in order to take advantage of opportunities or resolve costly incidents , which is why real-time anomaly detection is a necessity for modern businesses. The fact that a single company can actively monitor thousands or even millions of metrics means that the traditional approach of manually configuring static thresholds and monitoring metrics using reactive BI tools is insufficient. Instead, automated real time anomaly detection techniques must be used to deal with the scale and complexity of the data-driven economy.
Anodot’s spin on unsupervised anomaly detection techniques
Let’s discuss these anomaly detection techniques in more detail. Let’s consider a simple example of anomaly detection in which a retail store owner typically has an average of 100 customers each day and one day they experience a decrease in sales to 25 people that day, this would be very easy to detect without any tools. The store owner could also likely determine the cause of the downturn simply by talking to one of the customers.
Now, if we consider the same scenario but for an eCommerce store that gets one million site visitors a day and experiences a 75 percent decrease in sales, the root cause may be much more difficult to identify. It could be a result of a broken checkout process, a glitch in pricing, or an external factor such as Google algorithm update.
In the latter example, if the eCommerce business had been using modern anomaly detection techniques, the company would have likely been able to identify the anomaly in real time, correlate the metrics with each other to determine the root cause, and ultimately resolve the incident before sales were so severely impacted. This is exactly what Anodot’s real time anomaly detection with the use of a branch of artificial intelligence (AI) known as machine learning.
There are two main categories of machine learning methods: supervised and unsupervised. In a nutshell, supervised machine learning algorithms are trained with examples. Humans feed them datasets containing examples which are already labeled or categorized, which enables the algorithm to build a general model of each category. The algorithm then processes the real (uncategorized) data and attempts to put each item into one of the pre-learned categories. Since a supervised algorithm only knows the categories on which it has been trained, and its training was conducted on pre-labeled examples, a supervised machine learning algorithm cannot place an item into a category it has not seen an example of. This means that an automated anomaly detection system built on such an algorithm would have to be given examples of every single possible type of anomaly on every possible data distribution, pattern and trend. As you can imagine, this is not always practical given the sheer quantity and distribution of data generated today.
Unsupervised machine learning algorithms, on the other hand, learn what normal behavior is, and then apply a statistical technique to determine if a specific data point is an anomaly. A system based on this kind of anomaly detection technique is able to detect any type of anomaly, including ones which have never been seen before. The main challenge in using unsupervised machine learning methods for detecting anomalies is determining what is considered normal for a given time series.
At Anodot, we utilize a hybrid “semi-supervised” machine learning approach. The vast majority of the classifications are done in an unsupervised manner, yet customers can also give feedback, indicating “this is a real anomaly, but that is not a real anomaly.” This very small subset of all the examples that can be identified as one or the other provides valuable input into the mainly unsupervised system.
Unsupervised and Adaptive: Go with the flow (of anomaly detection)
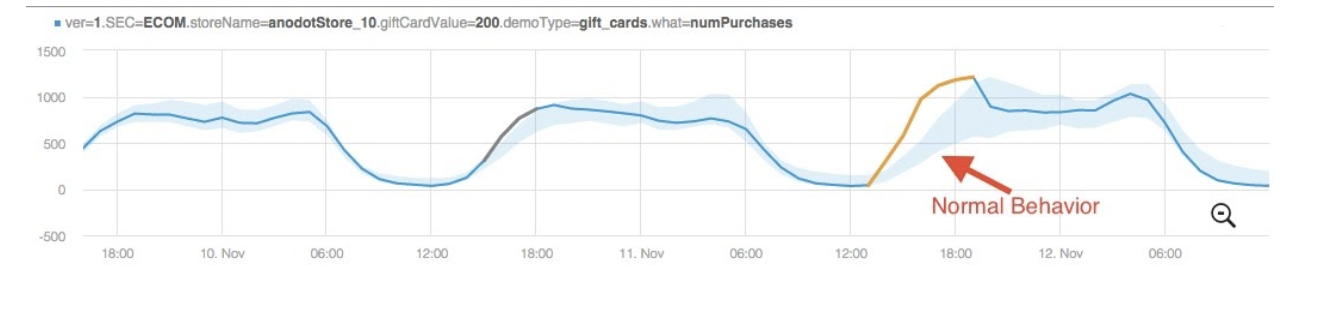
Not only are Anodot’s algorithms unsupervised, they are also adaptive, which means they adjust to and eventually accept changes in the time series as its normal behavior shifts over time. In the context of our retail store owner example, if the downturn in sales was due to a change in traffic patterns resulting in a permanent decrease in the number of store visitors each day, this would be reflected as the new normal behavior.
Anodot’s adaptive learning algorithms, being composed of computer instructions, achieve this same sort of adaptability by assigning an increasing weight to change the “normal” model the longer that anomaly persists. The result is an automated anomaly detection method which both flags anomalies, yet adapts to changes in the typical data patterns.
You can learn more about anomaly detection and adapting to normal behavior in our article on Preventing eCommerce Pricing Glitches with AI-Based Anomaly Detection.
Intelligent anomaly detection at each level
Once the anomalies are found by these interacting machine learning algorithms, a whole other layer of machine learning – one that utilizes deep neural networks, among other clustering and similarity algorithms – works to discover the relationships between metrics so that the flood of discovered anomalies can be distilled down to a much more manageable number of correlated incidents, which can then be investigated by human experts.
By filtering out the massive amount of data and pinpointing the issues at hand, we can extract actionable insights effortlessly from each anomaly, which empowers companies to turn incidents into opportunities and errors into learning curves.


