
At the advent of the technological era, developers found themselves wasting hours of valuable resources on manual QA. As software was released, teams manually confirmed that it was bug-free and reliable, all the while testing new features and checking for regression of existing features.
The Shift to Automated Testing
Unfortunately, this manual approach was prone to mistakes, created long delays in workflows and was tedious and time-consuming.
At some point, automated testing came along, and people were replaced by machines that ran code, which tested products automatically.
With automation, tests can be run overnight so developers can know if an app is valid or not by the next morning. Additionally, models used for QA don’t make mistakes, making testing more robust and reliable.
The Rise of CI/CD and Anodot’s Approach
Improving the efficiency of the testing process in this way allows companies to automatically deploy products to customers using a process known as CI/CD, or continuous integration and deployment.
At Anodot, we’ve created a fully automated CI/CD process, which includes:
- Non-manual testing
- Unit tests for backend functionality
- API system/integration tests
- UI integration tests
- Component testing
Each new feature is developed in a relevant feature-branch, which simulates the main branch.
Automating the Mundane
With Autonomous Analytics, Anodot is all about automating the mundane. We use Python to write the infrastructure for running tests and the Pytest library to create the tests.
Python allows us to create tests easily because of its simple syntax and its widespread use. Whenever we encounter a difficult issue, there are plenty of Python forums and sites to find the answer. Pytest introduces us to hooks so we can listen to common events and edit some of the test flow functionality according to our needs. Everything in Python is customizable, and Pytest contains many plugins which extends its functionality.
Two popular plug-ins that we use at Anodot are:
- Pytest-xdist, which runs tests concurrently, so we can distribute the tests among selenium grid nodes (discussed later in this post).
- Pytest-html, which converts the report from XML to HTML format, so we can display reports in Jenkins.
The CD/CI process relies on test automation to continue delivering the product. If any of these tests fail, regression follows. To ensure test results are valid, we use the flaky library to verify that all tests are reliable and that there aren’t any false positives or false negatives. This step helps reduce the likelihood of test failure to practically zero percent.
Running the tests distributed among selenium grid nodes works as follows:
- We set up selenium-grid as a microservice inside a container from a predefined docker.
- We define the selenium grid hub URL for the selenium RemoteDriver and use it in our tests (or infrastructure).
- A new test session is launched.
- Tests arrive to the selenium grid hub.
- The hub distributes the tests among the selenium nodes.
- Each selenium node runs its given test and reports back to the hub.
- The hub reports back the results to the test.
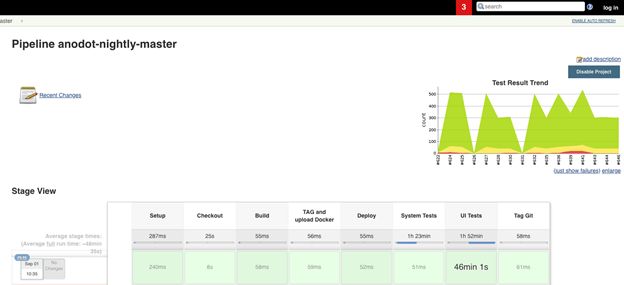
So now that we’ve got the code for testing, how do we integrate it into the CI/CD process? At Anodot, we mainly use Jenkins for deploying containers to any of our many Kubernetes environments. After the required tests are completed successfully, the valid container is deployed to our cluster.
Common Challenges
The main issue with test automation is making robust and valid tests that do not break, and display true classification value as a result.
Valid tests (true positives/negatives) will:
- Find a bug in the app.
- Pass only when the features are valid.
- Fail due to an environmental issue that cannot be recovered during the test; e.g., network failure or an inaccessible web page.
Invalid tests (false negatives/positives) will:
- Indicate a bug when the feature is working correctly.
- Not report an existing bug in the app.
- Display an error because the actual test code is problematic; e.g., showing an “Index out of bounds” error instead of “couldn’t create a metric”.
In order to keep a test: classification – true, we need to stabilize the test. This means we need to:
- Adjust to changes done by the web/client developers to the UI, as any UI change could prevent the test automation from accessing the UI elements on the website – such as textboxes, drop-down lists, etc.
- Add logging to our tests, so we can reproduce a failed test bug.
- Have a good infrastructure that will help us easily change tests according to continuous app changes in the UI or API.
Each test should also check for a single feature or aspect in an app. Nonetheless, sometimes a test will fail prematurely because one of the requirements was not met.
To demonstrate this issue, let’s assume we are testing an anomaly display in the Anodot platform’s Anoboard.
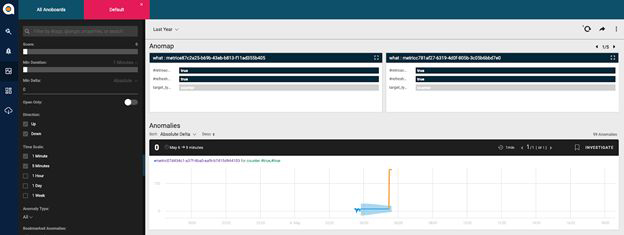
So what will the test include?
First, we’ll start by creating an anomaly, then we’ll check in the Anoboard to see if the anomaly actually shows up.
Let’s say we send an HTTP request to access the Anodot API in order to create a metric with an anomaly. Even if the call is successful, an existing bug would prevent the anomaly from being created. In this scenario, we check the Anoboard.
Although we’re expecting the created anomaly to be displayed as a tile, we can’t find it and need to report that the test failed due to a UI problem. This assumption is incorrect, because the anomaly wasn’t created in the first place. What we should do is check that the anomaly was actually created after having sent the HTTP request.
Conclusion
With the tools now available to software engineers, it’s easier than ever to convert manual tests into a more automated and streamlined CI/CD process. While this article covers the benefits of automated QA, it’s important to mention that there are still several issues that you could come across. In our upcoming post on infrastructure implementation, we’ll review potential roadblocks and provide a step-by-step guide to resolving them as you go.


