5G is in the process of transforming communications technology, enabling never-before-seen data transfer speeds and high-performance remote computing capabilities. As a cloud-native application, 5G provides advantages in terms of speed, agility, efficiency and robustness. But in order to reap the rewards inherent in 5G technology — mobility, low latency, high data rates, extreme reliability and vast scale — the 5G network’s engineering, operations and scaling have to be vastly different from all the previous generation of mobile technologies, across all layers.
The 5G network-as-application will need a different execution environment from first-generation virtual network functions (VNFs) that execute in virtual machine (VM)-based clouds. Ultra-reliable, low-latency communications, network slicing, edge services, and converged access hinges on CSP’s adoption of cloud-native technology and containers. Modern, cloud-native applications execute in lightweight container technology controlled by an orchestrator, be it Kubernetes, the de facto industry standard, or any other alternative.
Containers, micro-services and edge computing add another significant layer of complexity to the already compound Telco network. While operations and NOC teams are straining under the burden of facilitating availability and customer experience in the service layer, this new, highly fragmented infrastructure layer will demand increased resources and automation to keep on the rails.
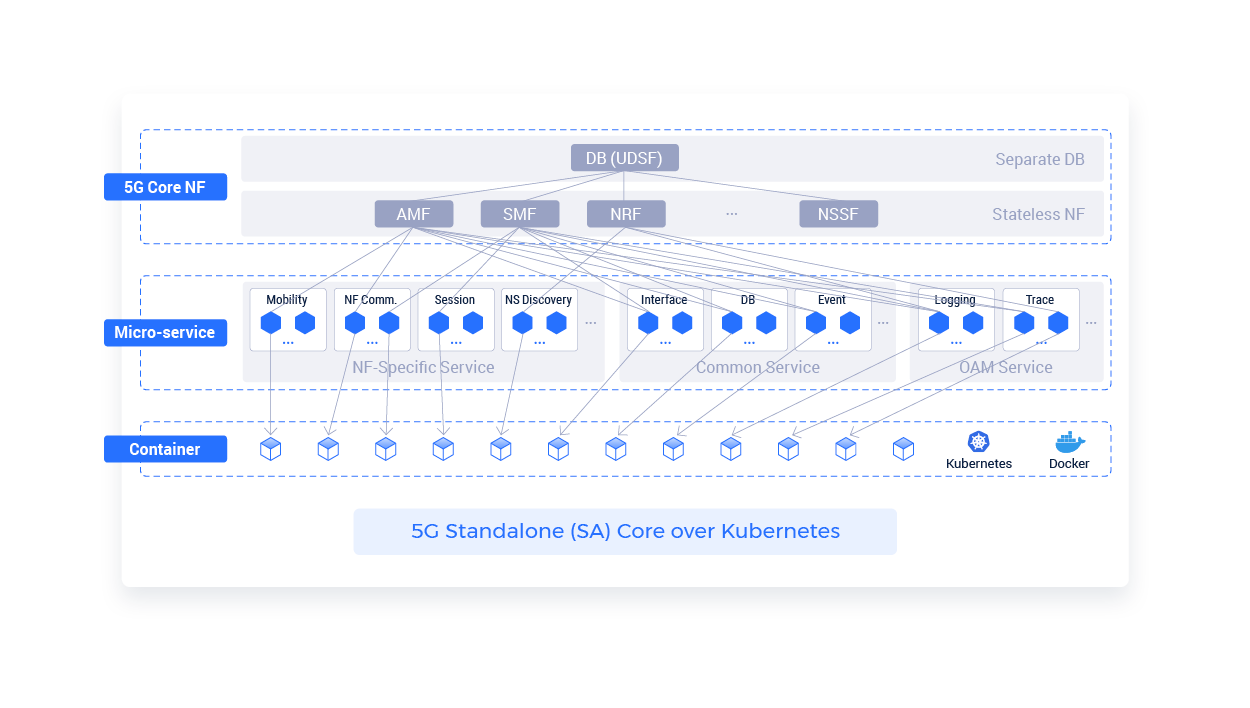
When every service can be located on a different micro-service, identifying service degradation or breakdown becomes extremely difficult. Uncovering dependencies and correlations for the root cause analysis required for rapid incident resolution demands complex investigations that cost valuable time and result in lost revenue, customers and brand equity.
Connecting Infrastructure and Service
Monitoring virtualized environments has never been easy. The growing adoption of microservices makes logging and monitoring more trying since it involves a large number of distributed and diversified applications constantly communicating with each other. Identifying failures is becoming increasingly difficult. On the other hand, a single glitch can kill the entire process. It’s not surprising that telcos list monitoring as a major obstacle for virtualized environments performance.
There are many available solutions for microservice management and monitoring, including the functionality inherent to the core technology itself, such as Kubernetes’ orchestration and self remediating abilities. However, for effective monitoring, it’s critical that your monitoring system automatically understands the severity of an incident and whether it has the potential to become catastrophic. This requires operation teams to create transparency across all network layers, and especially the ability to monitor the system, applications and services holistically. While microservices monitoring solutions excel in exposing anomalies occurring in the system layers, these are detached from their impact on service and applications, and may therefore be ineffective for preventing incidents that result in service degradation experience by customers.
That’s where Anodot’s complete visibility into 100% of the data, across layers, systems and silos, turns into a game changer for telecom operators. Anodot analyzes service data, virtualized systems data, IT data and telemetry to create end-to-end observability. By correlating between anomalies across the network layers, Anodot gives NOC teams the ability to immediately understand the connection between seemingly disparate incidents, expediting root cause analysis, remediation and resolution of glitches, service degradation and outages. Anodot stands out from other telecom monitoring solutions by creating 5G RAN and Core end-to-end network visibility through:
- Autonomously monitoring the microservices architecture health, from the user service quality to the backend storage, in a single platform
- Fast detection and learning through telemetry-backed real time monitoring that’s required by critical services.
- Scaling. Anodot runs in scale that can qualify as continuous monitoring of the 5G RAN and Core cloud native infrastructure, regardless of its extensive number of devices and layers.
- Cross Layer Correlation. Anodot detects and correlates anomalies across layers, including Service, Application, Clusters and Containers, for the fastest detection of critical incidents and root cause analysis.
- Remediation. Anodot’s self healing abilities are leveraged to remediate orchestration incidents within the virtualized environment.
From Reactive to Proactive Monitoring
As opposed to existing microservices orchestration and monitoring solutions, Anodot uses machine learning to detect anomalies. Since there is no manual thresholding, Anodot surfaces only critical incidents, preventing alert storms and redundant NOC teams investigations into false positives and false negatives. Teams using Anodot can therefore be more proactive in preventing and mitigating only and all the incidents that occur within the system layer but impact customers and revenue.
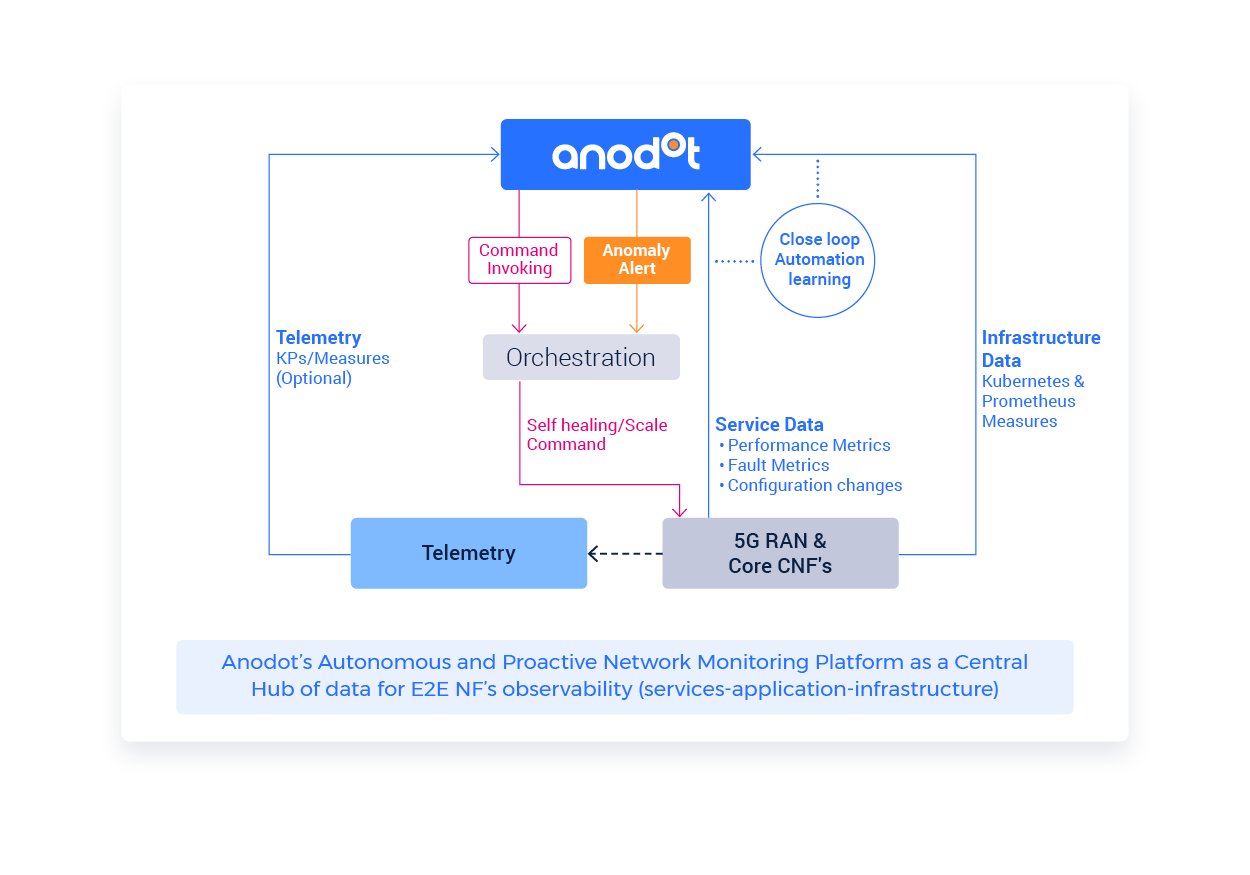
By adopting an AI monitoring system like Anodot, CSPs can use machine learning to constantly track millions of virtualized environments events in real time. Anodot’s anomaly detection solution creates a comprehensive view by monitoring the distributed environment and the applications themselves. Anodot automatically illuminates critical data blind spots for the shortest time to detection and resolution, so that NOC teams don’t miss customer impactful incidents in a sea of alerts.