
Costs of Unavailability
Availability is one of the key measurements for every company with an online presence. The expectation of customers is constantly increasing, and today they expect access to the service at any time, from any device. They expect nothing less than 100% availability. Measuring availability is a difficult but critical task. I strongly advise that no matter how difficult it is, you must take the time to define what availability means for your business and start tracking it.
The following table will help you understand the effect of different availability service level agreements (SLA) in terms of potential downtime:
| 99.9% | 99.95% | 99.99% | |
| Daily | 1m 26.4s | 43.2s | 8.6s |
| Weekly | 10m 4.8s | 5m 2.4s | 1m 0.5s |
| Monthly | 43m 49.7s | 21m 54.9s | 4m 23.0s |
| Yearly | 8h 45m 57.0s | 4h 22m 58.8s | 52m 35.7s |
Below, I share some of the potential impacts of unavailability. The emphasis you put on these factors will depend on the service being offered and your own circumstances.
Lost Revenue
If you are conducting business over the internet, every minute of downtime is directly linked to loss of revenue. There are different ways to calculate lost revenue:
- Determine how much revenue you make per hour, and use this as a cost to the enterprise for unavailability per hour/min. For example, in this article, Google’s cost of downtime was calculated at $108,000 per minute based on its Q2 2013 revenue of $14.1 billion. In another article, Facebook’s downtime cost was calculated at $22,453 per minute. This is the simple method, but it is not very accurate as revenue changes over time of day, day of week etc.
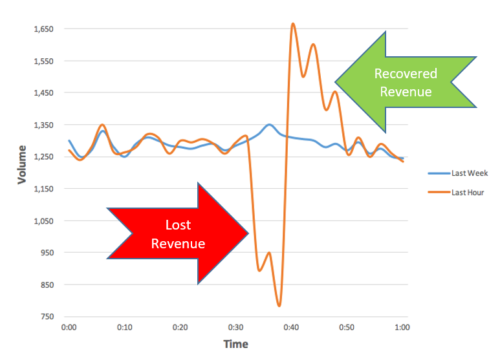
- Consider seasonality and recovered revenue, using week-over-week for a comparison of expected behavior vs. previous week. This is a more accurate method. In the following example, we see a significant drop in the transaction volume for about 10 minutes. Let’s assume that the revenue dropped by $110,000, and once the service was restored, users retried and completed their transactions resulting in an increase of $80,000. Now we can calculate the real impact as recovered revenue minus lost revenue: $80,000 – $110,000 = -$30,000 for those 10 minutes of downtime.
 Contractual Penalties
Contractual Penalties
Some organizations face financial penalties in the event of downtime. If your partners rely on your service being available, there is probably an SLA in place to guarantee certain availability. If this is not met, the provider must compensate the partner.
Negative Brand Impact
 Almost every online service, and definitely all mature services, has competition. Uber vs. Lyft, Airbnb vs. VRBO, hotels.com vs. booking.com, and so on. If one service is not available, it is very easy for customers to switch to the competition. The expectation of customers in today’s world is for the service to be available all the time.
Almost every online service, and definitely all mature services, has competition. Uber vs. Lyft, Airbnb vs. VRBO, hotels.com vs. booking.com, and so on. If one service is not available, it is very easy for customers to switch to the competition. The expectation of customers in today’s world is for the service to be available all the time.
In a previous post, we discussed the different elements of an incident life cycle. Major incidents are detected very easily, even with very basic monitoring in place. The real challenge is getting to the root cause of the issue and fixing it quickly. Even if you have the right set of signals across the entire technology stack including infrastructure, application and business metrics, the data most likely resides in silos. Because of this, the person that triages the issue doesn’t have complete visibility, so different teams must investigate the root cause simultaneously.
Adopting machine learning-based anomaly detection enables the processing of all relevant metrics in a single system. In this set up, if an anomaly is detected in one of the metrics, it is easier to correlate between all the other metrics and uncover the root cause much faster. In fact, a good anomaly detection system not only detects the issue faster and more accurately than traditional threshold-based alerts, it correlates across all relevant metrics and provides visibility to all other related anomalies.
Let’s look at an example of a drop in volume of a specific product in a specific country. In this case, the system sends an alert that an anomaly was detected on conversion rates in the specific country and will provide visibility into signals that may have caused the issue such as:
- Events that happened at the same time, like code push
- Another anomaly that occurred at the same time on the DB metrics
- Network metrics that might indicate DDOS attack
The idea is that with an anomaly alert, we will also receive other correlated events and anomalies to help us get to the root cause much faster by shortening the time it takes to triage the issue, thus reducing the impact on the business.


