
In today’s competitive market, digital businesses such as fintech, ad tech, media and others are always on the lookout for the next big thing to help streamline their business processes. These businesses are constantly generating new data and often have systems and people in place to monitor what is going on. For example, within one company, you might find an IT group monitoring network performance while someone in product management watching page response time and user experience while marketing analysts track conversions per campaign and other KPIs.
It is no secret that anomalies in one area often affect performance in other areas, but it is difficult for the association to be made if all the departments are operating independently of one another.
In addition, most of the available tools for this type of monitoring look at what has happened in the past, so there is a built-in delay between when something important happens, and when it may (or may not) be discovered via the monitoring process.
Each business incident discovered could be an opportunity to save money, plug a leaky funnel, or to potentially create new business opportunities.
In an ideal setting, a large-scale business incident detection system would take a holistic approach to anomaly detection, and do it in real time.
Monitoring and analyzing these data patterns in real-time can help detect subtle – and sometimes not-so-subtle – and unexpected changes whose root causes warrant investigation.
The graph below illustrates an e-commerce company that sees an unexpected increase in the number of gift cards purchased online while simultaneously experiencing a drop in the revenue expected for the gift cards. By correlating the two anomalies, we understand that there has been a price glitch that could cost the company a lot of money if not caught and addressed quickly.
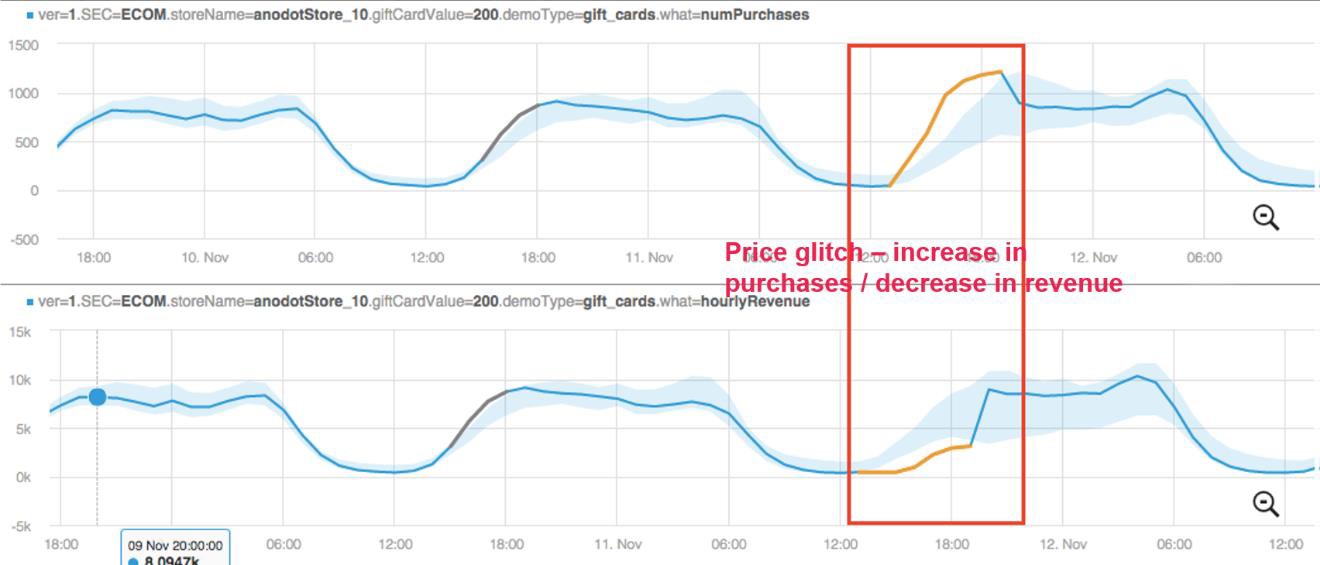
Price glitch that could cost ecommerce a lot of money
As a business grows, more and more incidents can go undetected unless an anomaly detection system is directed to make sense of the massive volume of metrics. Not every metric is directly tied to money—but most metrics are tied to revenue in some way. Today, most companies employ manual detection of anomalous incidents by creating a lot of dashboards and monitoring daily or weekly reports or by setting upper and lower alert thresholds for each metric. These methods leave a lot of room for human error and false positives or missed anomalies.
To find out how to leverage automated anomaly detection, where computers look at this data and sift through it automatically and quickly, to highlight abnormal behavior and alert on it, check out our White Paper: Building a Large Scale, Machine Learning-Based Anomaly Detection System, Part 1: Design Principles.


