
With the pandemic forcing businesses worldwide to reboot, many have no choice but to exact drastic cost-cutting measures to keep the lights on.
Cloud computing is an expense incurred by every digital business that, unlike many other operating costs, is largely variable. Cloud costs represent such a significant portion of a company’s operating budget that there is an emerging field called FinOps that specializes in merging engineers, developers and financial professionals in order to optimize these expenses.
In this guide, we’ll discuss exactly what strategic actions you can take in order to cut cloud costs, and lay out how our company used a plan that integrated AI-based monitoring to effectively cut $360K from our annual cloud costs.
Defining a Plan of Attack
Adapting to the new normal requires both a defensive and offensive strategy. One of the big pillars of our defensive strategy was to reduce our AWS bill, with the following core objectives:
- The cost reduction process needed to take no more than one month for the three engineers tasked with the objective.
- The changes need to fit seamlessly into our code base—in other words, we wanted as few code changes inside our app as possible.
- The changes needed to be sustainable, meaning that after implementation, the cost savings would persist over time.
With these objectives in mind, our team was split into two different groups—one tasked with performing our everyday work and the second dedicated to the cost-cutting mission. After a few internal discussions and research we decided there were four components to tackling this issue:
1. Reduce AWS Service Costs
Since our product uses many different AWS services, the first step was to figure out how to reduce costs on each of these services. To do so, we tagged each AWS resource individually so that we could know exactly how specific costs relate to specific components and environments. For example, we tagged all of our S3, EMR, and EC2 instances and looked at each one to figure out where we can reduce expenses through things like storing files more efficiently and compressing data before transferring it.
In terms of our S3 instance, when a sample comes into our system it is processed in real-time for our streaming service and also written in a log file for offline processing with our machine learning algorithms. On an hourly basis these files are uploaded to the S3 instance and a new file is created in the local machine. These files are written in plain text, and since inception have taken 200TB of size and cost us roughly $6,000 each month. We knew that we wanted a more efficient way to process these log files, so we started looking into alternatives.
To solve this, the first thing we did was change these files to Parquet files, which have the advantages of being a more compressed and efficient columnar data representation. In the end, we found the simplest and most effective solution was to compress the files with the open-source data collector FluentD. This change resulted in data that was 10 times smaller and savings of $5,000 each month.
In the case of our EMR instance we have a machine learning process each night that reads all the data from a S3 bucket and performs calculations and statistics for the data. We noticed that 80 percent of the process was spent reading data from the S3 bucket and bringing it into HDFS.
Now that we were performing the log compression in the S3 bucket, this resulted in significantly less processing time and allowed us to store files more efficiently, in particular this allowed us to go from an average size of textual files from 200MB to 18MB.
In the case of our EC2 instance, since we manage massive amounts of data with the Cassandra database, we have a large cluster consisting of 50 i3.2xlarge instances. In the past, a lot of our data was stored in JSON format there, but since we were a young startup it was still able to run fast. Also, having the data in a human readable format helped us a lot with debugging. We always knew we wanted to change this and store our data in a more efficient way, but we simply never got around to it. Given the chance to work on this cloud cost reduction task finally gave us the opportunity to correct this initial wrong doing.
The way we chose to store our data in a more efficient way was to do it with Kryo – on the one hand storing data in binary format meant that we wouldn’t be able to read the data by a simple query, but on the other hand we were able to create internal tools that made the querying and converting the data seamless. The cherry on top was that data was now stored much more efficiently, which reduced a significant amount of nodes in the Cassandra ring, consequently saving us a lot of money.
2. Changes in the Development Cycle
Next, we reviewed our development cycle and noticed that we could reduce costs in the development stage. We’re using Feature Branches, where each branch has its own development environment with all of our services.
We found that many of our services were not necessary at this stage and that our developers needed roughly half of the services in order to run and test new features. Now, when developers start a new feature we create a “mini-production” environment that uses the minimum operational size. In other words, we removed non-essential services, and the developer can then choose to add services into the workload as needed. This ultimately allowed us to reduce each cluster by roughly 50 percent of the original size.
We also decided that each one of these environments should “go to sleep” at night and on weekends since there was no need for them to be running during these times. This ended up reducing our workload at off-times by 60 percent.
Finally, we noticed that many of our developers were working on several different features at the same time—thus creating several different feature branches and environments that were running concurrently. Since no one can effectively work on two features at the same time, we decided to limit the number of awake environments that were up and running simultaneously.
3. Financial Planning
One of the key benefits from implementing these first two changes is that we were better able to predict our cloud usage and reserve instances, resulting in further cost savings. In particular, we made a transition from reserved instances (RI) and convertible RI to a savings plan. With a savings plan, we didn’t need to commit to reserving specific instance types or regions, and instead only needed to commit to an overall hourly spend. This ultimately gave us more flexibility to switch between instance types and higher cloud cost savings.
4. Monitoring our AWS Usage
Finally, after we initially optimized our AWS costs, we knew that we needed to stay on top of things, which meant real-time usage monitoring so there weren’t any surprise expenses. One of the main issues we found with relying on the AWS cost monitoring tools is that there’s a significant delay in the cost data since the CUR file is only ready after eight hours.
For this reason, we decided to take a machine learning-based approach to monitoring cloud usage since it has a direct correlation with our costs. As discussed in our white paper on business monitoring, tracking these business-oriented metrics posed a unique challenge for three main reasons:
- Context: Each business metric derives significance from its own unique context, and thus cannot be evaluated in absolute terms. For example, each cloud instance may have its own seasonal behavior based on the time of day, device, geographical region, and so on.
- Topology: Similarly, the fact that many cloud costs come from human-generated activity often means that business topology is unknown. For this reason, the relationships and correlations between metrics is incredibly dynamic and complex.
- Volatility: A final challenge arises from the fact that business metrics often have irregular sampling. In other words, there may be minutes or hours between cloud instances being used at their normal capacities.
To deal with these complexities, we determined that a machine-learning based monitoring system would be best-suited to monitoring each metric individually and also to correlating metrics using unsupervised learning techniques.
One example of the effectiveness of real-time monitoring occurred when our data science team was running experiments using an Amazon Athena service incorrectly. If this had gone unnoticed, the error would have cost us quite a bit over the course of 24 hours. Instead, the real time alert paired with a deep root cause analysis allowed us to resolve the error within 1 hour.
Cloud Cost Monitoring Alerts
We include several alerts we used to monitor several key AWS services:
S3
As mentioned, our S3 instance stores the samples in real time for our streaming service, and we wanted to monitor for sudden spikes in the S3 bucket size. In the image below, you can see that in the last month there were two anomalies detected: one was related to our Cassandra backup snapshots and the other to our helm charts. Monitoring our S3 bucket size has been critical to keeping costs low because when sudden spikes go undetected they can be quite costly.
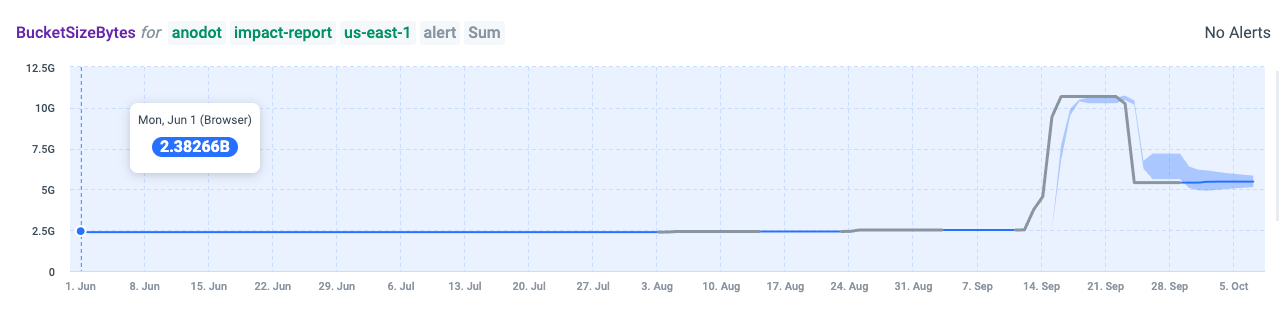
EC2
In terms of monitoring our EC2 instances, an effective way to keep costs down is to track the amount of virtual CPU in the account at any given time. For example, in the image below, there’s a spike in vCPU, which was caused by a data scientist running an experiment that was unintentionally spawning new machines. Luckily, thanks to the alert the team was notified in near real time and the experiments was stopped before incurring any significant costs:
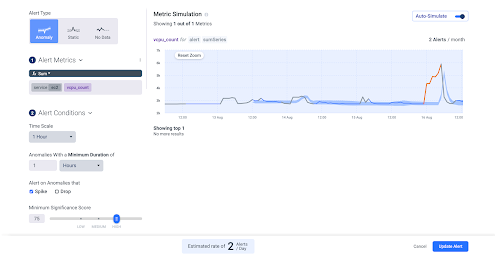
EBS
A final example of cloud cost alerts that saved us unnecessary expenses is monitoring our EBS instances. In this case, we wanted to know if there were any spikes in our unused EBS, although as you can see below there haven’t been any anomalies to warrant an alert as of yet:
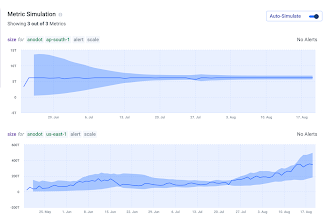
Summary: Cloud Cost Monitoring
For many companies, cloud computing costs represent a variable expense that can be optimized with the right monitoring system. The issue with many of the traditional monitoring tools is that they have a data lag, and when anomalies inevitably do occur, they can’t be resolved until after the cost has been incurred.
We opted for machine learning-based cloud cost monitoring because it offers the granularity to spot hard-to-detect anomalies, its immediacy, and the ability to correlate between related anomalies and the subsequent impact on time to resolution.
We started tagging resources, pinpointing costs, and monitoring usage in March, and by August our efforts indicated savings that will likely reach an anticipated $360K in annual cloud costs.
Interested in automating your cloud usage and cost monitoring? Check out Anodot’s business package for AWS – it only takes 3 steps to get started.
Start optimizing your cloud costs today!
Connect with one of our cloud cost management specialists to learn how Anodot can help your organization control costs, optimize resources and reduce cloud waste.
