
At Anodot, our solution analyzes the massive amount of metrics collected by data-centric businesses. These metrics originate from multiple sources, such as business processes, applications, systems, networks, and anything in between.
One important use case for the Anodot technology is the rapid detection of IT environment issues so that they can be fixed quickly. Our method for detection is to find anomalous behavior in the metrics. This type of behavior usually indicates an existing or impending problem.
Anodot for Anodot
A week before we released our alpha version to our first customers last October, we decided to let Anodot work on itself, that is, to detect its own anomalies. We started monitoring our systems and application components in order to generate our own business metrics.
One of our important business metrics is the number of anomalies we can detect per minute. For example an application metric is the average latency of a process running within our application. We started collecting large amounts of these metrics with the understanding that they would be important for keeping Anodot up and running.
Fast Self-Analysis
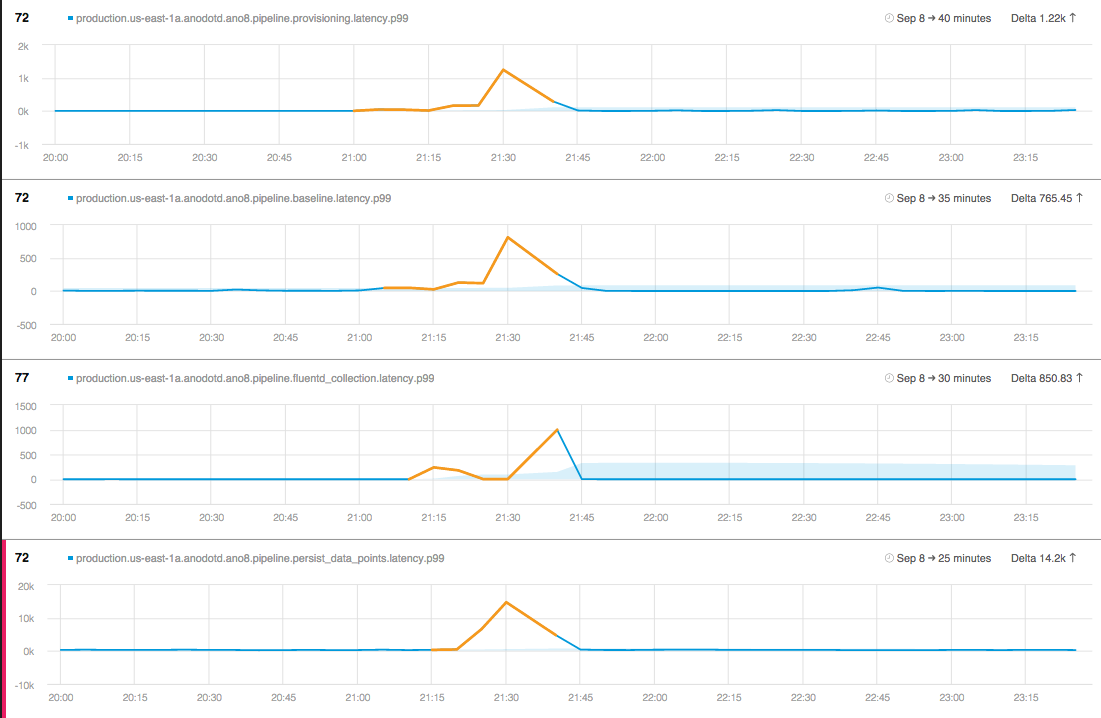
The decision to test our own system quickly yielded results. Just hours after the automatic self-analysis process commenced, our system found a strange anomaly: This anomaly lasted for 30 minutes and then stopped. In the anomaly, the latency of one of our processes went up dramatically for 0.1% of the times that the process ran, a few thousand times per minute. During the 0.1% of these occurrences, the latency rose from about a second to over 60 seconds! This meant that every once in a while, at unpredictable times, the process would take over 60 seconds to run.
If this issue were to occur at the same time that multiple Anodot users were attempting to view their systems, they could experience a lengthy delay (see charts below).
Counting on Anodot Rather than on Luck
The problem turned out to be a bug in our code, an unanticipated lock/sync problem. Understanding and fixing the bug was not difficult – however, we would not have been able to detect such intermittent problems with standard monitoring tools. The fact that we were using our own tools reinforced the market need for automatic anomaly detection. Without Anodot, we would have relied only on chance. By depending on manual monitoring, we would have needed to be lucky enough to look at the graphic metrics correctly, at exactly the time when the problem occurred. If we had missed this problem, we would have discovered it only if our users would have contacted us to complain about an intermittent latency problem.
Self-healing System?
Is this the first step towards an intelligent system that can heal itself? Perhaps. It certainly is evidence of an intelligent system, one that can detect its own bugs automatically, without requiring programmers to define how to look for the bugs. It is also a step in defining the essence of machine learning: Our algorithms don’t just power our system – they help fix it as well! Most importantly, by running Anodot on Anodot, we are able to provide a better, smoother experience to our customers.
Written by Ira Cohen
You'll believe it when you see it



