
As the complexity of Kubernetes environments grow, costs can quickly spiral out of control if an effective strategy for optimization is not in place. We’ve compiled expert recommendations and best practices for running cost-optimized Kubernetes workloads on AWS, Microsoft Azure, and Google Cloud (GCP).
What Is Kubernetes Cost Optimization?
Kubernetes cost optimization is the practice of maintaining Kubernetes infrastructure and workload performance while optimizing cost-efficiency to the max. In other words, it’s a way of improving your Kubernetes performance while maintaining reliability. This entails identifying areas of the Kubernetes environment that are less cost-efficient than others.
Cost optimization strategies include:
- Minimizing your number of servers and reducing environment services.
- Autoscaling your application or cluster to meet demands and saving costs by shutting down when demands decrease.
- Sharing resources across multiple servers.
- Optimizing network usage.
- Improving node configurations.
- Optimizing storage space.
- Regularly using sleep more.
The Importance of Kubernetes Cost Optimization
Kubernetes cost optimization is vital because of how much money it can save your organization while improving infrastructure value, operational efficiency, and scalability. It enables you to deliver high quality services while saving money on Kubernetes spend.
Without cost optimization, Kubernetes spend can become inefficient, leading to wasted resources, budgets, and your company time.

Melissa Abecasis
Director of Customer Success & Sr. Cloud FinOps Engineer, Anodot
Melissa brings a wealth of experience in customer success, cloud financial operations, and program management, with a demonstrated work history in the Information Technology and healthcare industry.
TIPS FROM THE EXPERT
1. Enable granular cost allocation with resource tagging
Tagging Kubernetes resources such as clusters, nodes, and pods by environment, team, or application allows for detailed cost tracking. This provides transparency into how much each project or team is consuming, helping drive accountability and cost optimization.
2. Use autoscaling to match demand dynamically
Take advantage of Kubernetes’ Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA) to dynamically scale your resources up and down based on real-time demand. Combine these with Cluster Autoscaler to adjust the number of nodes, avoiding over-provisioning and reducing idle costs.
3. Leverage spot instances for non-critical workloads
Use spot instances where possible to take advantage of the steep discounts (up to 90%) they offer compared to on-demand pricing. This is especially effective for fault-tolerant and batch workloads that can tolerate interruptions.
4. Reduce network data transfer costs
Design your Kubernetes topology to minimize cross-region or cross-availability zone (AZ) communication. Keeping traffic within the same zone avoids unnecessary data transfer fees that can quickly add up, especially for high-traffic applications.
5. Continuously monitor resource utilization
Use cost monitoring tools like Anodot to gain real-time visibility into Kubernetes resource utilization and cost anomalies. This allows for faster detection of inefficiencies or misconfigurations and helps you take corrective actions promptly.
Which Factors Contribute to Kubernetes Costs?
Something important to note is that there is no one thing that leads to your Kubernetes bill breaking your budget. The tricky part of Kubernetes cost optimization is that often a lot of very small costs can pile up, unnoticed, in the background. The following are all factors that are likely contributing to your Kubernetes bill:
- Compute costs. Since Kubernetes requires compute resources to power workloads and operate the control panel, it can be tricky to keep track of how much you’re spending. Monitor how many applications you’re running and keep an eye on the number of servers that you join to your clusters – because that’s all going on your bill!
- Storage costs. Kubernetes storage costs vary depending on your chosen storage class and the amount of data you want to store. For example, costs vary enormously depending on if you use HDD or SSD storage.
- Network costs. If you’re using a public cloud to run Kubernetes, you need to pay networking costs. This includes degrees fees, fees which cloud provides require when you move data from their cloud to another infrastructure.
- External cloud service costs. Depending on how many third-party services and APIs you use in your Kubernetes clusters, your external cloud services costs might be quite high. Your bill will increase depending on the type of service, the amount of data or calls exchanged, and the service-specific pricing model.
What Are Kubernetes Cost Optimization Tools?
If you’re looking for the best way to improve your Kubernetes spend without spending hours of your time combing through data, you need a Kubernetes optimization tool. Kubernetes optimization tools provide a real-time view into your cloud usage. Expect granular levels of detail about cost and resource allocation, as well as spending anomaly detection and budget forecasting.
A Kubernetes optimization tool can improve anything from organizational visibility into the cloud, task automation for scaling and cost management, deployment scalability, to regular updates and support.
Considering adding a Kubernetes cost improvement tool to your digital suite? Anodot provides Kubernetes cloud cost management tool to help you optimize your cloud spend so you can put your dollars to work elsewhere.
Gaining Complete Kubernetes Cost Visibility
Gaining visibility into your container cost and usage data is the first step to controlling and optimizing Kubernetes costs. Visibility is critical at each level of your Kubernetes deployment:
Clusters
Nodes
Pods (Namespaces, Labels, and Deployments)
Containers
You will also want visibility within each business transaction. Having deep visibility will help you:
- Avoid cloud “bill shock” (a common compelling incident where stakeholders find out after-the-fact that they have overspent their cloud budget)
- Detect anomalies
- Identify ways to further optimize your Kubernetes costs
For example, when using Kubernetes for development purposes, visibility helps you identify Dev clusters running during off-business hours so you can pause them. In a production environment, visibility helps you identify cost spikes originating from a deployment of a new release, see the overall costs of an application, and identify cost per customer or line of business.
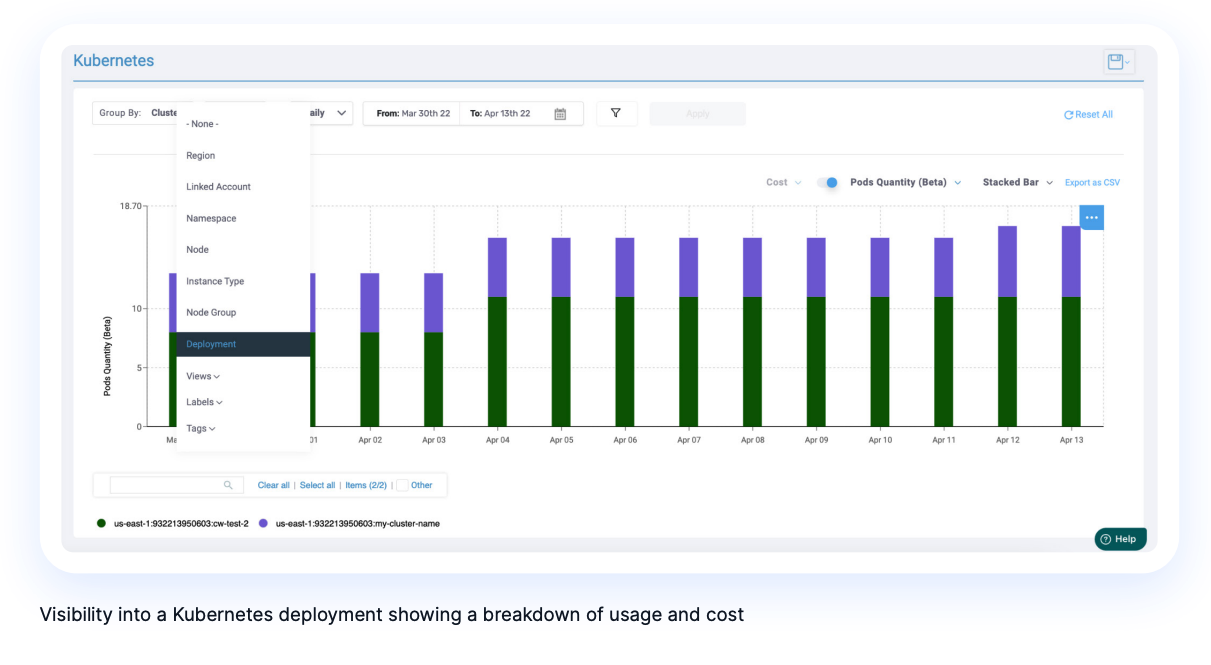
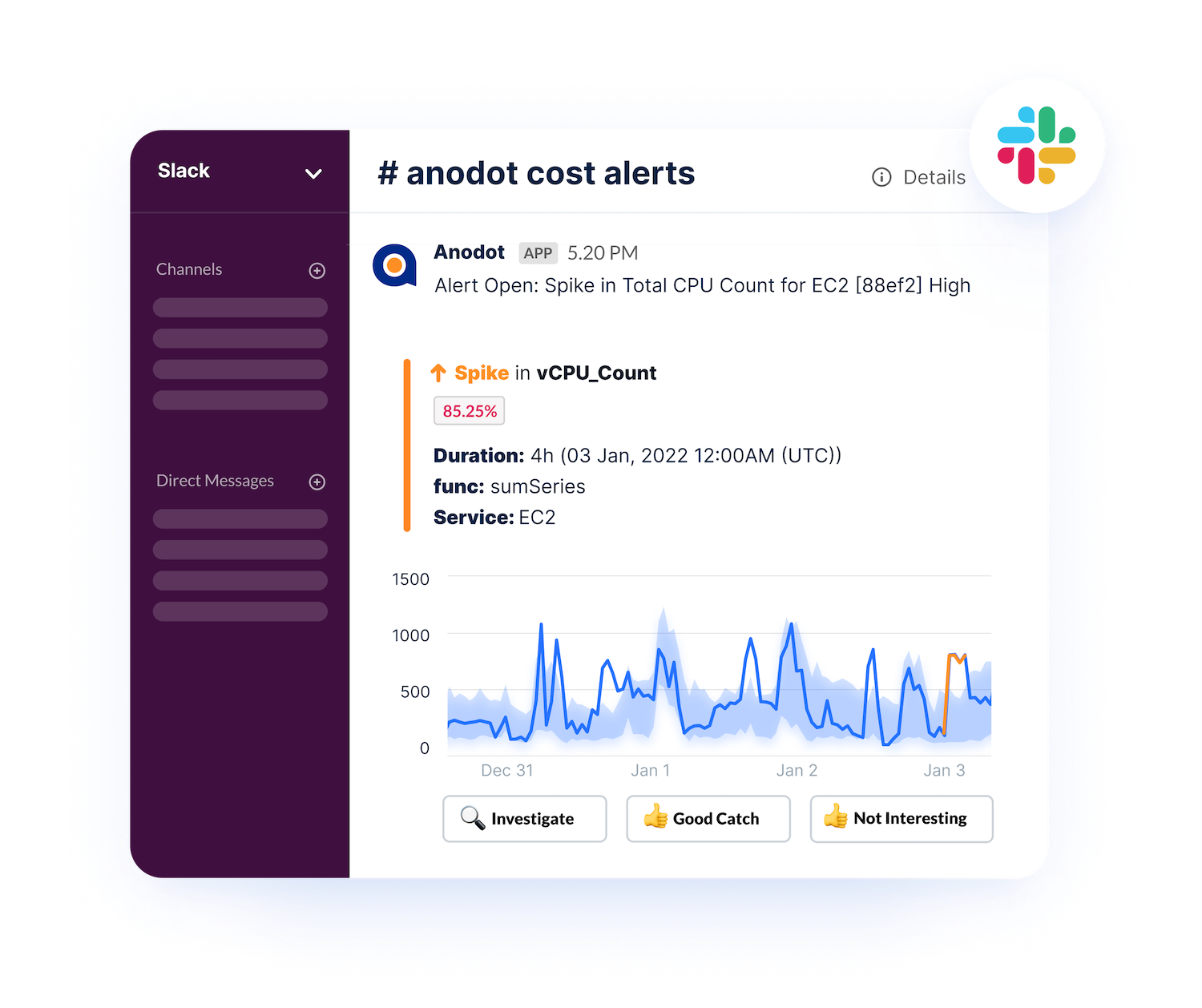
Detecting Kubernetes Cost Anomalies
“Bill shock” is too common an occurrence for businesses that have invested in Kubernetes. Anomaly detection intelligence will continuously monitor your usage and cost data and automatically and immediately alert relevant stakeholders on your team so they can take corrective action.
Anomalies can occur due to a wide variety of factors and in many situations. Common anomaly causes include:
- A new deployment consuming more resources than a previous one
- A new pod being added to your cluster
- Suboptimal scaling rules causing inefficient scale-up
- Misconfigured (or not configured) pod resource request specifications (for example, specifying GiB instead of MiB)
- Affinity rules causing unneeded nodes to be added
Save your team the pain of end-of-month invoice shock. Any organization running Kubernetes clusters should have mechanisms for K8s anomaly detection and anomaly alerting in place — full stop.

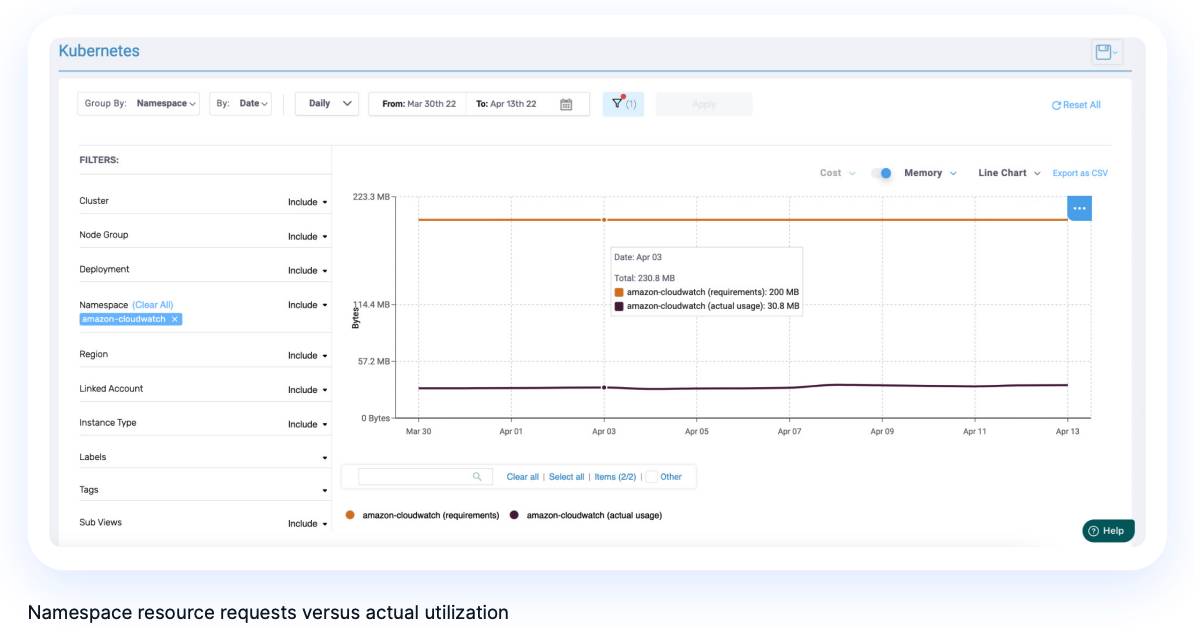
Optimizing Pod Resource Requests
Have organizational policies in place for setting pod CPU and memory requests and limits in your YAML definition files. Once your containers are running, you gain visibility into the utilization and costs of each portion of your cluster: namespaces, labels, nodes, and pods. This is the time to tune your resource request and limit values based on actual utilization metrics.
Kubernetes allows you to fine-tune resource requests with granularity up to the MiB (RAM) and a fraction of a CPU, so there is no reason to overprovision and end up with low utilization of the allocated resources.
Node Configuration
Node cost is driven by various factors, many of which can be addressed at the configuration level. These include the CPU and memory resources powering each node, OS choice, processor type and vendor, disk space and type, network cards, and more.
When configuring your nodes:
- Use open-source OSes to avoid costly licenses like those required for Windows, RHEL, and SUSE
- Favor cost-effective processors to benefit from the best price-performance processor option:
- On AWS, use Graviton-powered instances (Arm64 processor architecture)
- In GCP, favor Tau instances powered by the latest AMD EPYC processors
- Pick nodes that best fit your pods’ needs. This includes picking nodes with the right amount of vCPU and memory resources, and a ratio of the two that best fits your pod’s requirements.
- For example, if your containers require resources with a vCPU to memory ratio of 8, you should favor nodes with such a ratio, like:
- AWS R instances
- Azure Edv5 VMs
- GCP n2d-highmem-2 machine types
- In such a case, you will have specific nodes options per pod with the vCPU and memory ratio needed.
- For example, if your containers require resources with a vCPU to memory ratio of 8, you should favor nodes with such a ratio, like:
Processor Selection
For many years, all three leading cloud vendors offered only Intel-powered compute resources. But, recently, all three cloud providers have enabled various levels of processor choice, each with meaningful cost impacts. We have benefited from the entry of AMD-powered (AWS, Azure, and GCP) and Arm architecture Graviton-powered instances (AWS).
These new processors introduce ways to gain better performance while reducing costs. In the AWS case, AMD-powered instances cost 10% less than Intel-powered instances, and Graviton instances cost 20% less than Intel-powered instances. To run on Graviton instances, you should build multi-architecture containers that comply with running on Intel, AMD, and Graviton instance types. You will be able to take advantage of reduced instance prices while also empowering your application with better performance.
Purchasing Options
Take advantage of cloud provider purchasing options. All three leading cloud providers (AWS, GCP, Azure) offer multiple purchasing strategies, such as:
- On-Demand: Basic, list pricing
- Commitment-Based: Savings Plans (SPs), Reserved Instances (RIs), and Commitment Use Discounts (CUDs), which deliver discounts for pre-purchasing capacity
- Spot: Spare cloud service provider (CSP) capacity (when it is available) that offers up to a 90% discount over On-Demand pricing
Define your purchasing strategy choice per node, and prioritize using Spot instances when possible to leverage the steep discount this purchasing option provides. If for any reason Spot isn’t a fit for your workload — for example, in the case that your container runs a database — purchase the steady availability of a node that comes with commitment-based pricing. In any case, you should strive to minimize the use of On-Demand resources that aren’t covered by commitments.
Autoscaling Rules
Set up scaling rules using a combination of horizontal pod autoscaling (HPA), vertical pod autoscaling (VPA), the cluster autoscaler (CA), and cloud provider tools such as the Cluster Autoscaler on AWS or Karpenter to meet changes in demand for applications.
Scaling rules can be set per metric, and you should regularly fine-tune these rules to ensure they fit your application’s real-life scaling needs and patterns.
Kubernetes Scheduler (Kube-Scheduler) Configuration
Use scheduler rules wisely to achieve high utilization of node resources and avoid node overprovisioning. As described earlier, these rules impact how pods are deployed.
In cases such as where affinity rules are set, the number of nodes may scale up quickly (e.g., setting a rule for having one pod per node).
Overprovisioning can also occur when you forget to specify the requested resources (CPU or memory) and instead, only specify the limits. In such a case, the scheduler will seek nodes with resource availability to fit the pod’s limits. Once the pod is deployed, it will gain access to resources up to the limit, causing node resources to be fully-allocated quickly, and causing additional, unneeded nodes to be spun up.
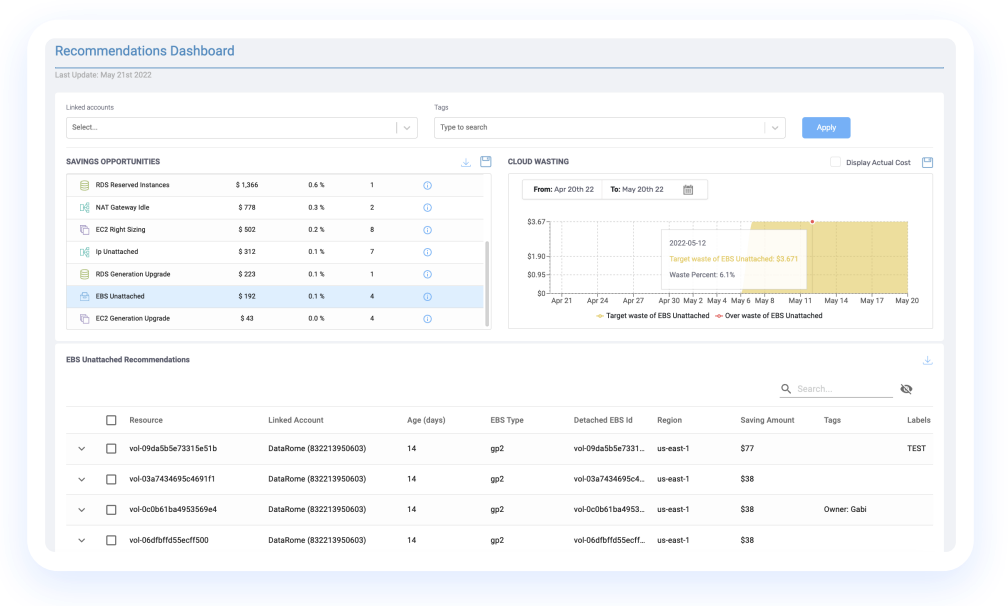
Managing Unattached Persistent Storage
Persistent storage volumes have an independent lifecycle from your pods, and will remain running even if the pods and containers they are attached to cease to exist. Set a mechanism to identify unattached EBS volumes and delete them after a specific period has elapsed.
Optimizing Network Usage to Minimize Data Transfer Charges
Consider designing your network topology so that it will account for the communication needs of pods across availability zones (AZs) and can avoid added data transfer fees. Data transfer charges may also happen when pods communicate across AZs with each other, with the control plan, load balancers, and with other services.
Another approach for minimizing data transfer costs is to deploy namespaces per availability zone (one per AZ), to get a set of single AZ namespace deployments. With such an architecture, pod communication remains within each availability zone, preventing data transfer costs, while allowing you to maintain application resiliency with a cross-AZ, high-availability setup.
Minimizing Cluster Counts
When running Kubernetes clusters on public cloud infrastructure such as AWS, Azure, or GCP, you should be aware that you are charged per cluster.
In AWS, you are charged $73 per month per cluster you run with Amazon Elastic Kubernetes Service (EKS). Consider minimizing the number of discreet clusters in your deployment to eliminate this additional cost.
Mastering Kubernetes Cost Optimization
Now that you have a better understanding of Kubernetes cost optimization strategies, it’s time to implement best practices for maximizing your Kubernetes ROI.
Optimize: Leverage intelligent recommendations to continuously optimize Kubernetes costs and usage
After enabling appropriate visibility across all your stakeholders, you and your FinOps team can finally take on the task of optimizing and reducing Kubernetes spending. With comprehensive K8s visibility, you can fine-tune Kubernetes resource allocation — allocating the exact amount of resources required per cluster, namespace/label, node, pod, and container.
Operate: Formalize accountability and allocation for Kubernetes costs
As a FinOps strategy leader, you must gain consensus and instill proper financial control structures for Kubernetes within your organization. FinOps strategies without accountability and alignment are doomed to failure. Financial governance controls further reduce the risk of overspending and improve predictability. This operating phase is where the rubber meets the road as far as what results you will gain from your Kubernetes FinOps efforts.
Learn details on these strategies to maximize K8s ROI here
Anodot for Kubernetes Cost Optimization
Anodot provides granular insights about your Kubernetes deployment that no other cloud optimization platform offers. Easily track your spending and usage across your clusters with detailed reports and dashboards. Anodot’s powerful algorithms and multi-dimensional filters enable you to deep dive into your performance and identify under-utilization at the node level.
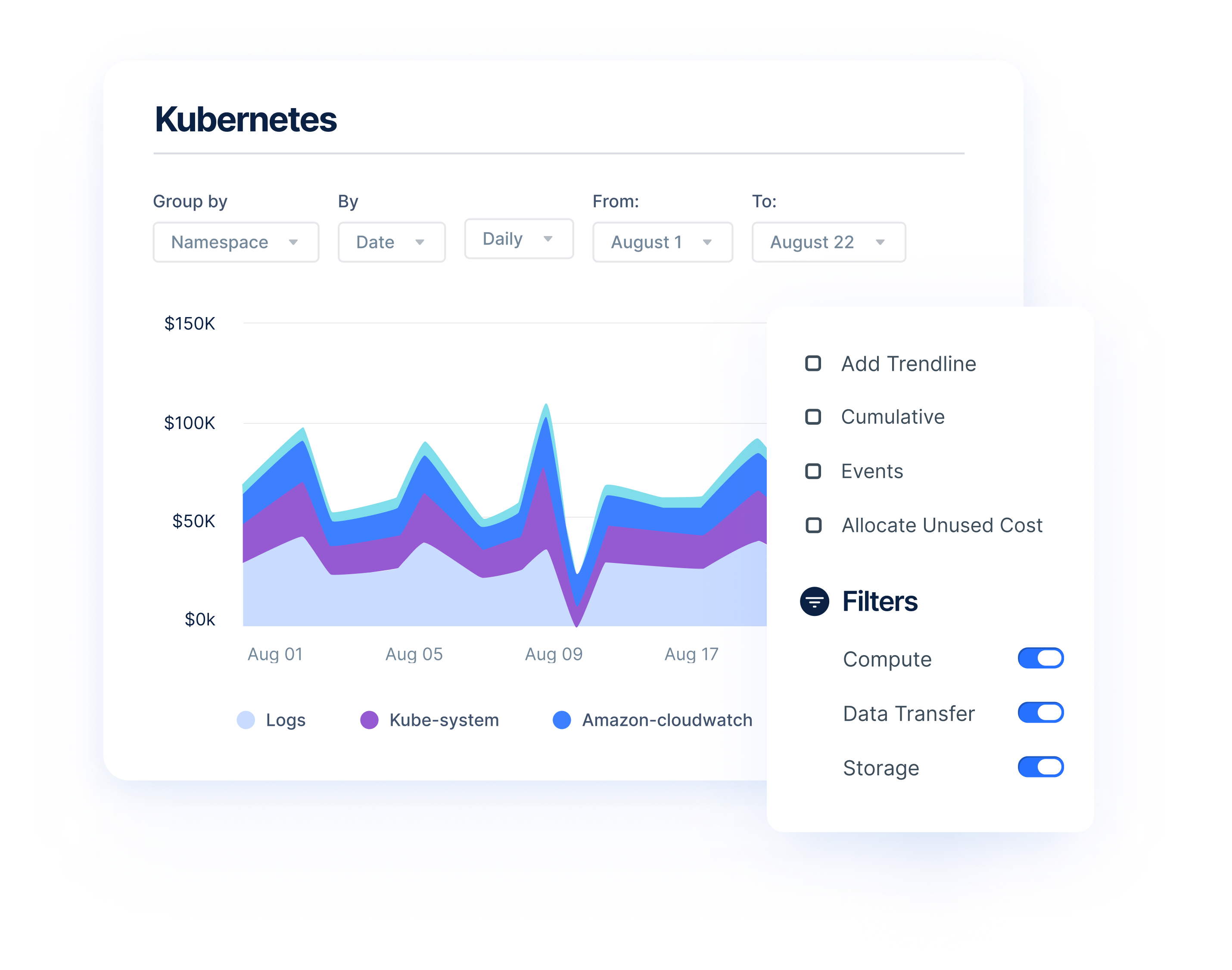
With Anodot’s continuous monitoring and deep visibility, engineers gain the power to eliminate unpredictable spending. Anodot automatically learns each service usage pattern and alerts relevant teams to irregular cloud spend and usage anomalies, providing the full context of what is happening for the fastest time to resolution.
Anodot seamlessly combines all of your cloud spend into a single platform so you can optimize your cloud cost and resource utilization across AWS, GCP, and Azure. Transform your FinOps, take control of cloud spend and reduce waste with Anodot’s cloud cost management solution. Getting started is easy! Book a demo to learn more.
Written by Anodot
Start Reducing Cloud Costs Today!
Connect with one of our cloud cost management specialists to learn how Anodot can help your organization control costs, optimize resources and reduce cloud waste.



