
Understanding Kubernetes Cost Drivers
Optimizing Kubernetes costs isn’t an easy task. Kubernetes is as deep a topic as cloud (and even more complex), containing subtopics like:
- Scheduler and kernel processes
- Resource allocation and monitoring of utilization (at each level of K8s infrastructure architecture)
- Node configuration (vCPU, RAM, and the ratio between those)
- Differences between architectures (like x86 and Arm64)
- Scaling configuration (up and down)
- Associating billable components with business key performance indicators (KPIs)
- and much more!
That’s a lot for a busy DevOps team to understand and manage, and doesn’t even consider that line-of-business stakeholders and finance team members should have some understanding of each cost driver’s function and importance to contribute to a successful FinOps Strategy.
Following is a description of the seven major drivers of Kubernetes costs, the importance and function of each, and how each contributes to your cloud bill. These descriptions should be suitable for the consumption of all business stakeholders, and can be used to drive cross-functional understanding of the importance of each cost driver to Kubernetes FinOps.
The Underlying Nodes
Most likely, the cost of the nodes you select will drive a large portion of your Kubernetes costs. A node is the actual server, instance, or VM your Kubernetes cluster uses to run your pods and their containers. The resources (compute, memory, etc.) that you make available to each node drive the price you pay when it is running.
For example, in Amazon Web Services (AWS), a set of three c6i.large instances running across three availability zones (AZs) in the US East (Northern Virginia) region can serve as a cluster of nodes. In this case, you will pay $62.05 per node, per month ($0.085 per hour). Selecting larger instance sizes, such as c6i.xlarge, will double your costs to $124.1 per node per month.
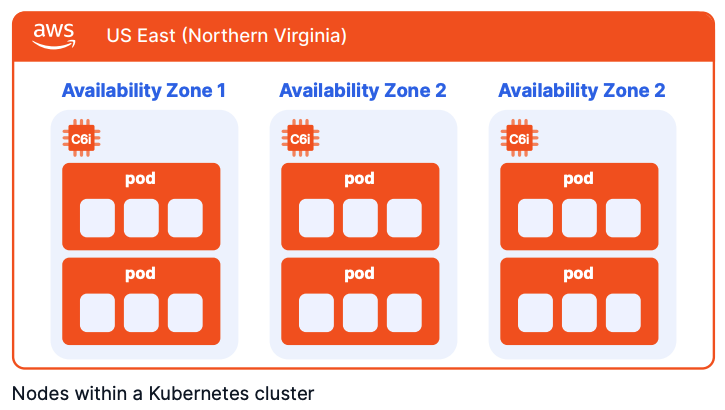
Parameters that impact a node’s price include the operating system (OS), processor vendor (Intel, AMD, or AWS), processor architecture (x86, Arm64), instance generation, CPU and memory capacity and ratio, and the pricing model (On-Demand, Reserved Instances, Savings Plans, or Spot Instances).
You pay for the compute capacity of the node you have purchased whether your pods and their containers fully utilize it or not. Maximizing utilization without negatively impacting workload performance can be quite challenging, and as a result, most organizations find that they are heavily overprovisioned with generally low utilization across their Kubernetes nodes.

Request and Limit Specifications for Pod CPU and Memory Resources
Your pods are not a billable component, but their configurations and resource specifications drive the number of nodes required to run your applications, and the performance of the workloads within.
Assume you are using a c6i.large instance (powered with 2 vCPUs and 4 GiB RAM) as a cluster node, and that 2 GiB of RAM and 0.2 vCPUs are used by the OS, Kubernetes agents, and eviction threshold. In such a case, the remaining 1.8 vCPU and 2 GiB of RAM are available for running your pods. If you request 0.5 GiB of memory per pod, you will be able to run up to four pods on this node. Once a fifth pod is required, a new node will be added to the cluster, adding to your costs. If you request 0.25 GiB of memory per pod, you will be able to run eight pods on each node instance.
Another example of how resource requests impact the number of nodes within a cluster is a case where you specify a container memory limit, but do not specify a memory request. Kubernetes automatically assigns a memory request that matches the limit. Similarly, if you specify a CPU limit, but do not specify a CPU request, Kubernetes will automatically assign a CPU request that matches the limit. As a result, more resources will be assigned to each container than necessarily required, consuming node resources and increasing the number of nodes.
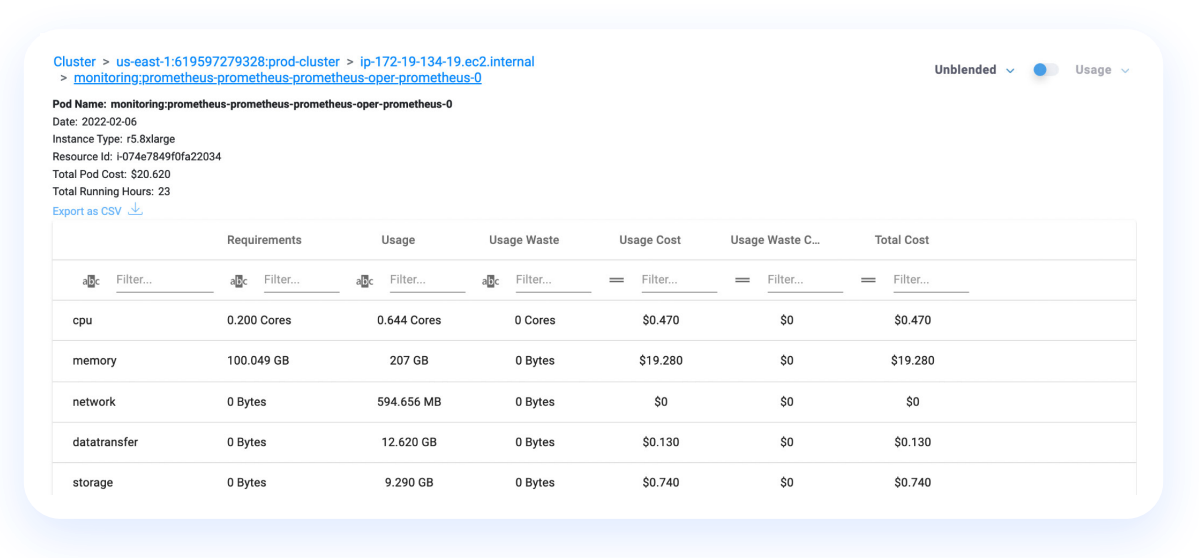
In practice, many request and limit values are not properly configured, are set to defaults, or are even totally unspecified, resulting in significant costs for organizations.
Persistent Volumes
Kubernetes volumes are directories (possibly containing data), which are accessible to the containers within a pod, providing a mechanism to connect ephemeral containers with persistent external data stores. You can configure volumes as ephemeral or persistent. Unlike ephemeral volumes, which are destroyed when a pod ceases to exist, persistent volumes are not affected by the shutdown of pods. Both ephemeral nor persistent are preserved across individual container restarts.
Volumes are a billable component (similar to nodes). Each volume attached to a pod has costs that are driven by the size (in GB) and the type of the storage volume attached — solid-state drive (SSD) or hard disk drive (HDD). For example, a 200 GB gp3 AWS EBS SSD volume will cost $16 per month.
Affinity and The K8s Scheduler
The Kubernetes scheduler is not a billable component, but it is the primary authority for how pods are placed on each node, and as a result, has a great impact on the number of nodes needed to run your pods.
Within Kubernetes, you can define node and pod affinity (and pod anti-affinity), which constrains where pods can be placed. You can define affinities to precisely control pod placement, for use cases such as:
- Dictating the maximum number of pods per node
- Controlling which pods can be placed on nodes within a specific availability zone or on a particular instance type
- Defining which types of pods can be placed together
- and powering countless other scenarios
Such rules impact the number of nodes attached to your cluster, and as a result, impact your Kubernetes costs.
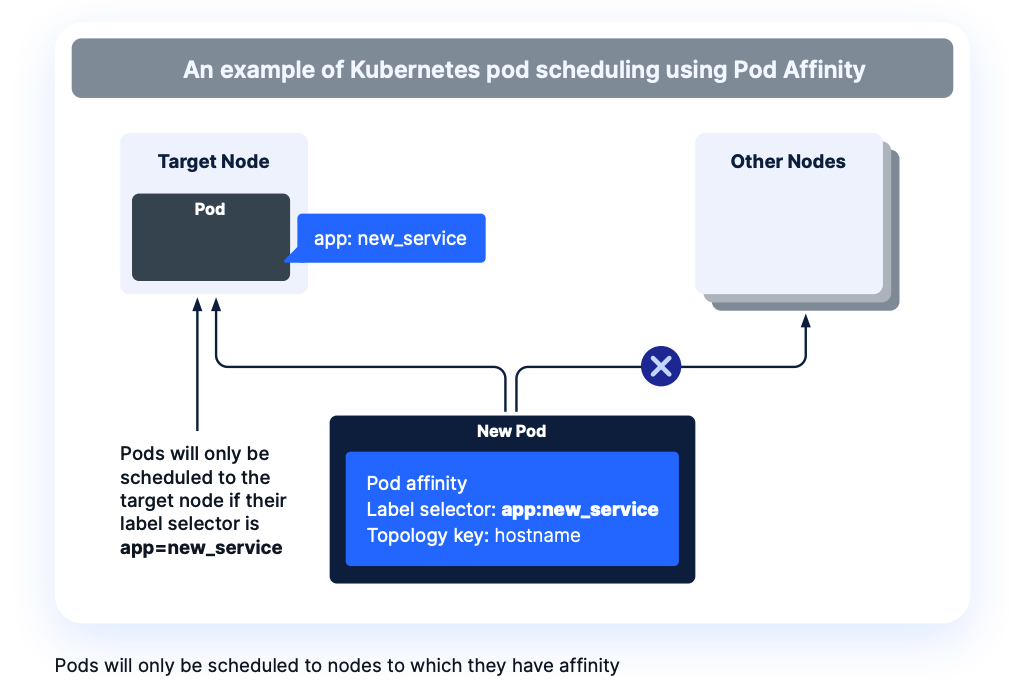
Consider a scenario where an affinity is set to limit pods to one per node and you suddenly need to scale to ten pods. Such a rule would force-increase the number of nodes to ten, even if all ten pods could performantly run within a single node.
Data Transfer Costs
Your Kubernetes clusters are deployed across availability zones (AZs) and regions to strengthen application resiliency for disaster recovery (DR) purposes, however data transfer costs are incurred anytime pods deployed across availability zones communicate in the following ways:
- When pods communicate with each other across AZs
- When pods communicate with the control plane
- When pods communicate with load balancers, in addition to regular load balancer charges
- When pods communicate with external services, such as databases
- When data is replicated across regions to support disaster recovery
Network Costs
When running on cloud infrastructure, the number of IP addresses that can be attached to an instance or a VM is driven by the size of the instance.
For example, an AWS c6i.large instance can be associated with up to three network interfaces, each with up to ten private IPv4 addresses (for a total of 30). A c6i.xlarge instance can be associated with up to four network interfaces, each with up to 15 private IPv4 addresses (for a total of 60).
Now, imagine using a c6i.large instance as your cluster node, while you require over 30 private IPv4 addresses. In such cases, many Kubernetes admins will pick the c6i.xlarge instance to gain the additional IP addresses, but it will cost them double, and the node’s CPU and memory resources will likely go underutilized.
Application Architecture
Applications are another example of non-billable drivers that have a major impact on your realized Kubernetes costs. Often, engineering and DevOps teams will not thoroughly model and tune the resource usage of their applications. In these cases, developers may specify the amount of resources needed to run each container, but pay less attention to optimizations that can take place at the code and application level to improve performance and reduce resource requirements.
Examples of application-level optimizations include using multithreading versus single-threading or vice versa, upgrading to newer, more efficient versions of Java, selecting the right OS (Windows, which requires licenses, versus Linux), and building containers to take advantage of multiprocessor architectures like x86 and Arm64.
Optimizing Kubernetes Costs
As the complexity of Kubernetes environments grow, costs can quickly spiral out of control if an effective strategy for optimization is not in place. The key components to running cost-optimized workloads in Kubernetes include:
- Gaining complete visibility – Visibility is critical at each level of your Kubernetes deployment, including the cluster, node, pod and container levels.
- Detecting Kubernetes cost anomalies – Intelligent anomaly detection solutions continuously monitor your usage and cost data and immediately alert relevant stakeholders on your team so they can take corrective action.
- Optimizing pod resource requests – Once your containers are running, you gain visibility into the utilization and cost of each portion of your cluster. This is the time to tune your resource requests and limit values based on actual utilization metrics.
- Node configuration – Node cost is driven by various factors which can be addressed at the configuration level. These include the CPU and memory resources powering each node, OS choice, processor type and vendor, disk space and type, network cards, and more.
- Autoscaling rules – Set up scaling rules using a combination of horizontal pod autoscaling (HPA), vertical pod autoscaling (VPA), the cluster autoscaler (CA), and cloud provider tools such as the Cluster Autoscaler on AWS or Karpenter to meet changes in demand for applications.
- Kubernetes scheduler configuration – Use scheduler rules to achieve high utilization of node resources and avoid node over provisioning. In cases such as where affinity rules are set, the number of nodes may scale up quickly.
Anodot for Kubernetes Cost Management
Anodot’s cloud cost management solution gives organizations visibility into their Kubernetes costs, down to the node and pod level. Easily track your spending and usage across your clusters with detailed reports and dashboards. Anodot provides granular insights about your Kubernetes deployment that no other cloud cost optimization platform offers.
By combining Kubernetes costs with non-containerized costs and business metrics, businesses get an accurate view of how much it costs to run a microservice, feature, or application.
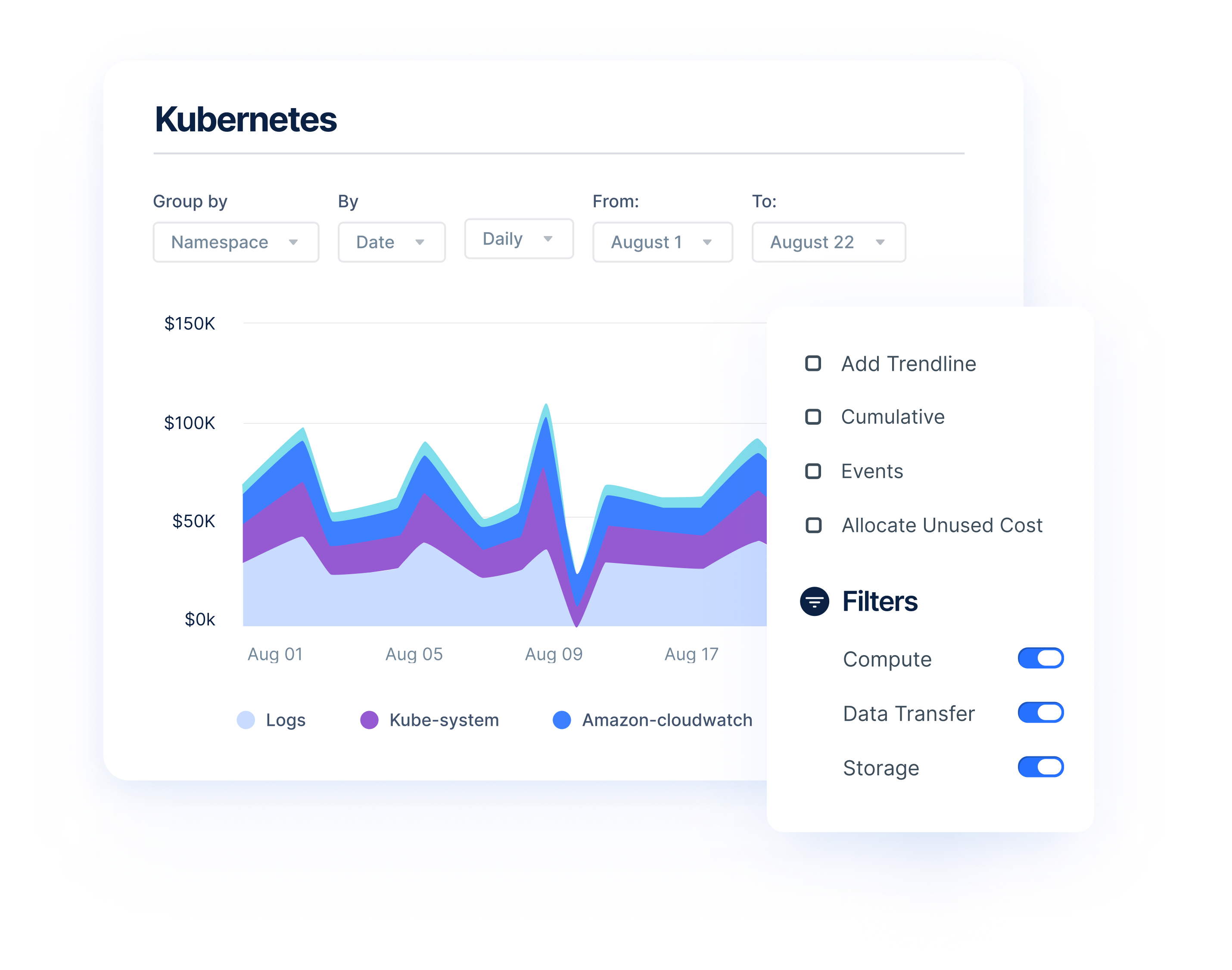
Anodot’s powerful algorithms and multi-dimensional filters also enable you to deep dive into your performance and identify under-utilization at the node level.
To keep things simple, the solution seamlessly combines all of your cloud spend into a single platform so you can optimize your cloud cost and resource utilization across AWS, GCP, and Azure.
Written by Anodot
Start Reducing Cloud Costs Today!
Connect with one of our cloud cost management specialists to learn how Anodot can help your organization control costs, optimize resources and reduce cloud waste.



