
Detection is only the first step: what makes automated anomaly detection truly automated?
Throughout this series on ‘why anomaly detection is a business essential,’ we have repeatedly mentioned the main drawback of manual anomaly detection: it simply can’t scale to a large number of metrics. This is why it’s necessary to use an automated anomaly detection system — because automation is the only way to monitor metrics at scale. But how many metrics is a question worth exploring, because answering it demonstrates the compounding costs which manual anomaly detection incurs on the businesses which use it – costs completely avoided when you automate.
Why manual anomaly detection is not viable
The first level of costs is the linear increase in personnel required. Let’s take a look at Anodot’s automated anomaly detection system: it uses machine learning techniques to detect anomalies in real time and then assigns those detected anomalies a numerical ranking based on their significance before finally grouping related anomalies together for concise reporting. Imagine a manual system using people for each step – detecting, ranking and grouping – and how much longer and less precise that would be.
First, let’s assume that each person can only perform real-time anomaly detection and ranking for 100 metrics at once (we’re assuming no automated alerts via thresholds). This means that for 1000 metrics, 10 people will be needed to monitor them. This personnel cost scales linearly with the number of metrics: 10,000 metrics would require 100 people, and 1 million metrics would require 10,000 people — at an approximate cost of $778,800,000, based on the salary for an entry-level data scientist.
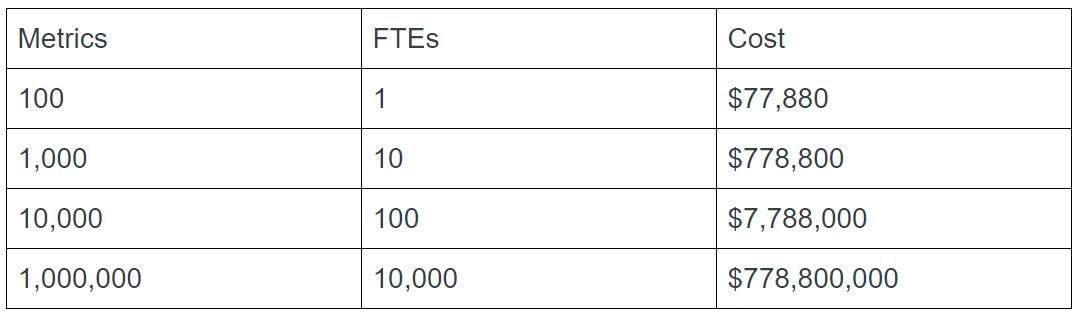
For comparison, Google’s parent company, Alphabet, now employs around 100,000 people — and we can safely assume that they have far more than a million metrics to monitor.
Then there’s the ranking. There are inherent problems of the inconsistency of one person’s quantitative ranking over time and the difference in ranking anomalies between people.
Since these rankings are used for filtering out insignificant anomalies, inconsistent rankings will result in important anomalies being missed and insignificant anomalies passing the filter. Even if a company could afford an army of analysts, Metcalfe’s Law shows that the communication overhead needed for all those analysts to group discovered anomalies in order to achieve concise reporting increases far faster than the headcount does.
To see why, consider again 10 analysts each monitoring 1,000 metrics. When one of them detects an anomaly, he or she may confer with the other 9 analysts to see if any of them detected an anomaly at the same time, and if so, discuss whether and how those detected anomalies are related. This requires a line of communication to exist between any two analysts (so that any single analyst may speak to any other). In our small group of 10, this means 45 total lines of communication are required to be open within this group.
One thousand, however, is a small number of metrics. What about our second group of 1,000 people monitoring a total of 100,000 metrics? That group would require 499,500 communication connections. Increasing our group size by a factor of 100 increased the number of required connections by a factor of 11,100. Manual anomaly detection in real time becomes impossible long before you reach 1 million metrics (which would require about 5 billion connections).
Although each analyst would only have to handle a small share of that overhead (999 connections for an analyst in our second example), time consumed by that overhead is time that can’t be spent detecting or ranking anomalies. As this communication overhead grows with the number of metrics, each person is less effective. An analyst might be able to monitor 100 metrics in a small group, but perhaps only 80 in a group twice as large.
This is just the cost incurred by communication itself, independent of any practical channel for that communication. Switching from emails to Slack won’t reduce this inherent cost of group intercommunication. This point is also made by Fred Brooks in his famous book on software development, The Mythical Man-Month.
Automated anomaly detection is the key to scaling
Anodot’s real-time, large-scale automated anomaly detection system is truly automated at each step in the process: detection, ranking, and grouping. It’s this completely automated approach that allows Anodot’s system to scale.
This completely automated system is made possible by using the machine learning method (or blend of methods) best for each layer. In previous posts, we discussed how our platform combines supervised and unsupervised machine learning methods to detect anomalies and how univariate and multivariate anomaly detection methods are used to provide very specific indicators of what’s anomalous while at the same time giving a more holistic picture of what’s going on behind the data.
After all, you just can’t afford to have 100,000 analysts between your data and your decisions.
Written by Ira Cohen
Ready to see our solution in action?
Prepare to see how Anodot leverages AI to constantly monitor and correlate business performance, identify revenue-critical issues, and provide real-time alerts and forecasts.


