An abundance of information can be daunting for any company. If internal teams do not know where the data is, it might hamper their efficiency at the cost of data quality and cleanliness.
From a cost-effectiveness viewpoint, organizations are likely to waste excessively by hanging on to redundant data or storing varied data in one location irrespective of their sensitivity level. With the exponential growth of data in recent years, organizations of all sizes have had to change both their organizational structures and technical stacks to successfully detect, diagnose, and fix events.
A Reasonable Approach to Remediation
Manual incident remediation takes time, is vulnerable to error, and turns out to be a safety concern for companies. Uptime Institute reports that more than 70 percent of data center outages occur due to human error, it does not come as a surprise that this outrage can bring down the most powerful tech to its knees.
Artificial intelligence-based monitoring and remediation technology is being applied across layers of the business to provide next-level incident management. Those solutions work at the speed and scale of modern business and, when properly trained, can find and fix issues before users even notice.
But why is it then that automated remediation still has its challenges? For the promise of automated remediation to be realized, there are conditions organizations must meet – some of those include continuous monitoring, cross-silo visibility, and highly accurate correlation analysis.
A Step-by-Step Guide to Automated Remediation
If having technology that independently detects, analyzes, and remediates business incidents sounds enticing, join the club. The promise is exciting but the reality is complicated. These eight essential components are what automated remediation will depend on to (hopefully) operate successfully.
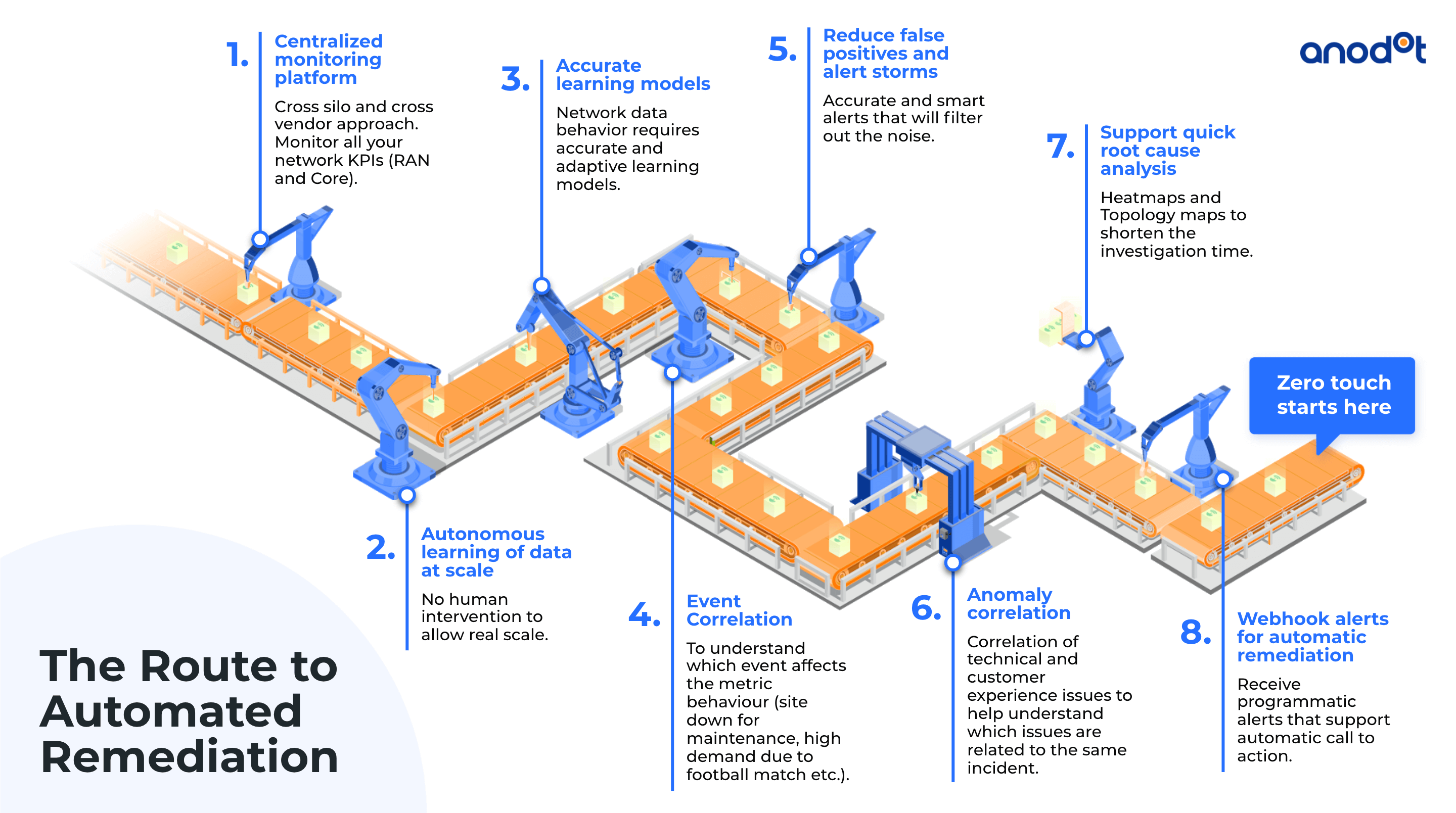
Step 1: Centralized monitoring platform
The first component is a centralized monitoring platform to provide a detailed look into every system’s KPIs. This ensures that departments obtain data without any hindrance under a data-agnostic monitoring system.
Step 2: Autonomous learning of metric behavior
The goal should be for near real-time remediation. For issues to be fixed immediately, the monitoring solution in place should be able to detect underlying patterns and learn the different metrics behaviors. Reducing human intervention in the early stages of your process can be a game-changer for greater scalability.
Step 3: Accurate learning models
Business data is diverse and continuously evolving. The machine learning models at play must be highly adaptive to metrics’ changing patterns. As conditions change, the gap will widen between trained data models and the actual real-time data, triggering false positives and irrelevant predictions. It’s incredibly important that the models are continuously re-trained to ensure that the data coming in is as close to real-time as possible.
Step 4: Event Correlation
This is one of the steps that connects the detection to the remediation. Correlating anomalies to the events that influence them is a must for root cause analysis. This process identifies relationships between metrics and the events that impact how they behave, for example, connecting site down-time to maintenance, or unusually high demand to a promotion.
AIOps uses machine learning strategies that lower the time and effort required to fit incidents in any modified IT infrastructure. This is typically done by calculating abnormal similarity, which calculates the correlation between multiple metric anomalies.In 5 Best Practices for Using AI to Monitor Your Kubernetes Environment Automatically, Anodot’s Head of DevOps writes, “Decisions such as when to wake up at night, when to scale out, or when to back pressure must be taken automatically.”
While strides have been made in correlating events to hardware metrics, making those connections for business metrics proves exponentially more challenging.
Step 5: Reduce False Positives and Alert Storms
A higher number of false positives can lead to alert fatigue, which, in turn, leads to a large number of ignored alerts risking the business. Enhancing accuracy across the system will be essential to getting the best results and user experience. Accuracy will depend on the models and how they’re selected and trained, but it will also depend on the detection capabilities, and how the alerts are tuned. Additionally, teams can reduce false positives by gathering data and feedback from end-users and embedding it into machine learning models to further improve each alert’s usefulness.
Step 6: Anomaly correlation
The next step towards automated remediation is correlating anomalies with one another. Data correlation is the method of corresponding one data set with the other, similar to the way in which features correspond to outputs in machine learning. In comparison, the anomaly correlation of technical, business, and customer experience metrics allows the ML system to understand the issues that relate to the same incident.
Anodot Chief Data Scientist Ira Cohen says of correlation analysis, “Applying anomaly detection on all metrics and surfacing correlated anomalous metrics helps draw relationships that not only reduce time to detection (TTD) but also support shortened time to remediation (TTR).”
Step 7: Support quick root cause analysis
Several of the capabilities described here work together to automate and accelerate root cause analysis, including:
- learning the norm
- detecting what is not normal
- understanding the anomaly significance
- identifying the leading dimensions
- correlating anomalies with related events and anomalies
When this task is automated, it will keep teams from spending hours debugging, tracking, and looking for what’s causing the incident.
Step 8: Custom actions for automatic remediation
The final step in the race to remediation involves receiving programmatic alerts that enable an automatic call to action. Data systems and servers can produce large amounts of log data about literally anything that happens on the server. Error? It’s in the logs. HTTP request? It’s also in the logs.
Adding webhooks listeners helps to orchestrate specific processes efficiently without unneeded delays, and it optimizes resource usage on involved platforms. Monitoring these webhooks is a game-changer, as it enables greater visibility, real-time insights, and even proactive business planning through advanced forecasts.
Summary
The shift from reactive to proactive methods of remediation owes itself to the technological advances in AI analytics. AI can track any layer of organizational information individually and precisely, delivering extremely reliable and real-time alerts. This paradigm shift towards artificial intelligence allows teams to identify and fix challenges more efficiently, resulting in improved customer experience and much lower incident costs.
The suggested eight steps might look like the finishing points, but they are only the beginning of Zero Touch NOC.
Written by Yariv Zur
You'll believe it when you see it



